21、数据库:读性能要如何提升?
- no21:数据库工程架构,要设计些什么呢?
- 1.根据「业务模式」设计库表结构
- 2.根据「访问模式」设计索引结构
- no21:数据库工程架构必须要考虑哪 5 个因素?
- 读性能提升
- 高可用
- 一致性保障
- 扩展性
- 垂直拆分
- no21:提升数据的读性能的方案一:建立索引
- 潜在问题
- 写性能降低
- 索引占用内存大,buffer命中率降低, 读性能降低
- 实践:可以为主实例不建立索引,从实例建立不同的索引
- 潜在问题
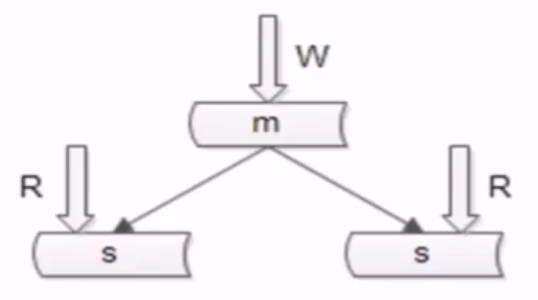
- no21:提升数据的读性能的方案二:增加从库
- 分组架构,主要解决的,就是读性能提升的问题,但没有解决数据容量的扩展以及写高可用的问题,分组会引发主从一致性问题,从库越多,同步越慢,主从一致性的问题就越严重

- no21:提升数据的读性能的方案三:增加缓存
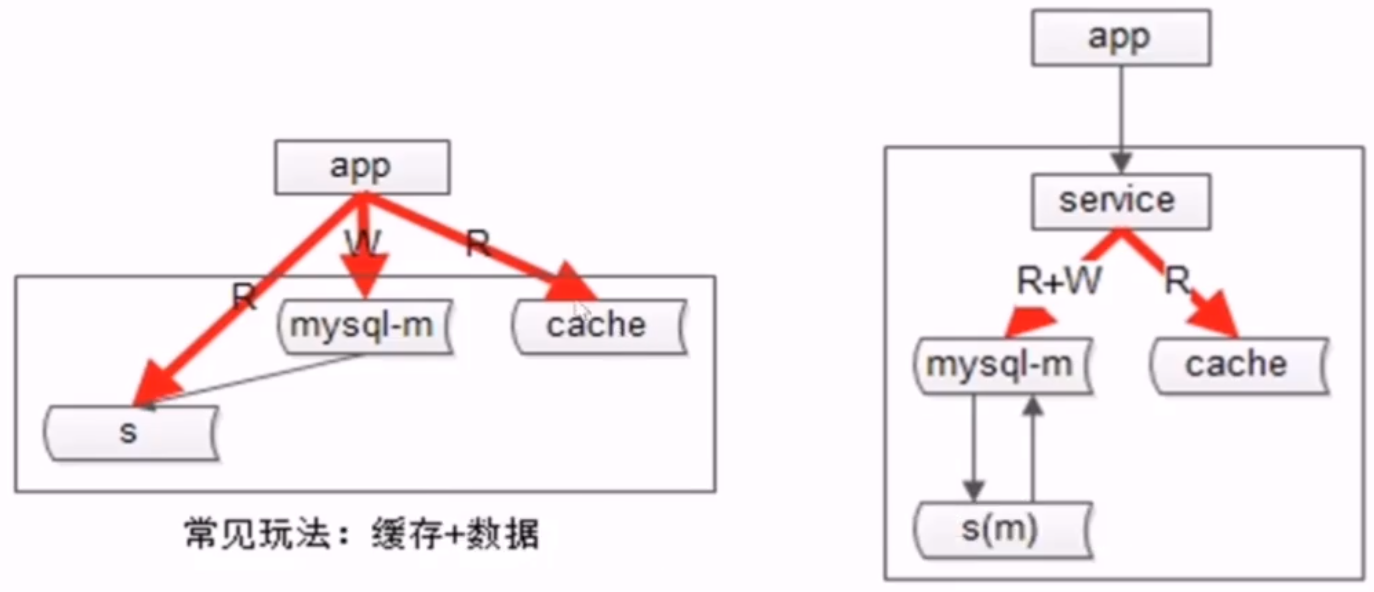
- 左边是服务化前,右边是服务化后,s 是从库,m 是主库
22、数据库:垂直拆分与高可用
- no22:数据库垂直拆分的方法论是什么?
- 1.长度较短
- 2.访问频率较高
- 3.经常一起访问
- 的属性放在主表里,原因是,数据库缓冲池,逻辑上,以 row 为单位缓冲数据
- no22:数据库的高可用的思路和问题是什么?
- 数据库的高可用设计,也是冗余+故障自动转移
- 但是,方法论上:数据库的冗余,会引发一致性问题!因为多个节点数据库没办法同时修改,中间会有个时间差,就有可能引发一致性的问题
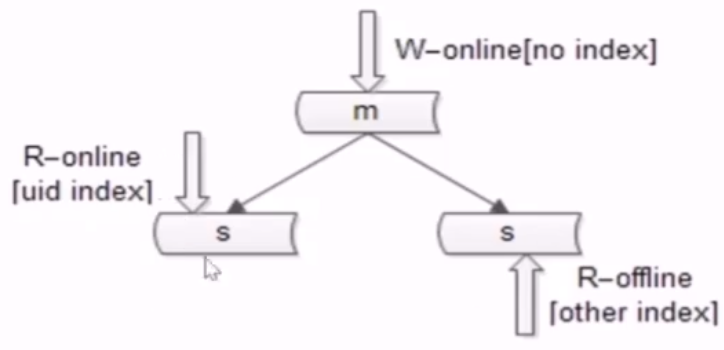
- no22:读库高可用的方案
- 读库高可用,冗余从库,可一主多从,主库会把主库的写序列通过 binlog 的方式同步给从库,重复执行相同的序列
- no22:写库高可用的方案
- 写库高可用,冗余写库,
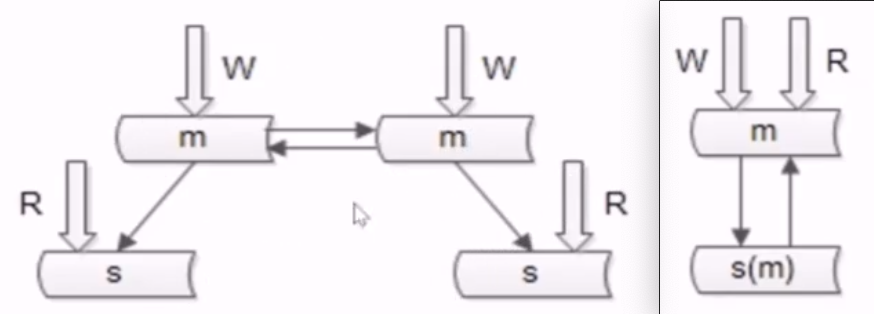
- 1.双主同步一个节点对外提供读写服务,另一个节点是备份节点,他们之间使用相同的 vip,通过 keepalived 去检测
- 2.在分组架构中加入一个双主节点,冗余写库,两边进行相互的同步,两个主库同时对线上提供服务
23、数据库:主从一致性,主主一致性如何保障?
- no23:主从数据冗余,主从数据不一致的情况是怎样?

- 应用写一个数据后,在主从数据库同步完成前读同一个数据,造成数据不一致
- no23:主从数据冗余,主从数据不一致的 3 个解决方案是什么?
- 方案一:忽略不计
- 中间时间估计约几百毫秒,业务允许的情况下,可不做处理
- 方案二:强制读主
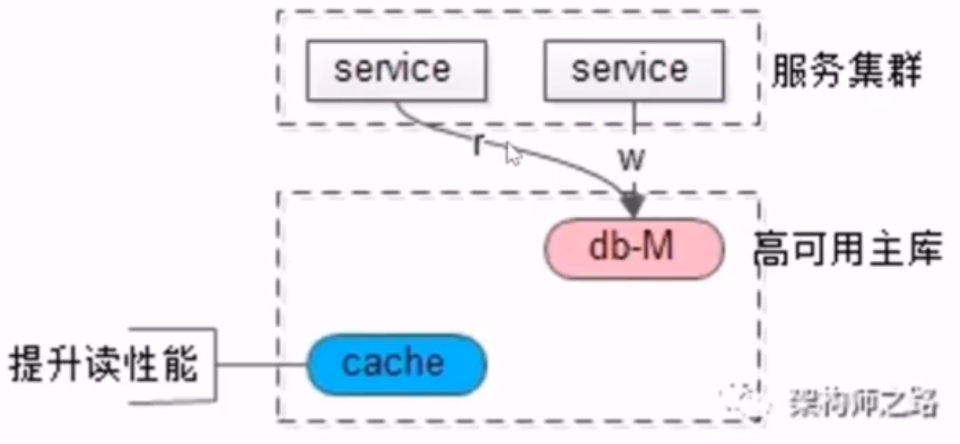
- 都读写主库,然后使用缓存来提升读性能,但主库和缓存间也有一致性问题
- 方案三:选择性读主(需要缓存协助)
- 写操作过程
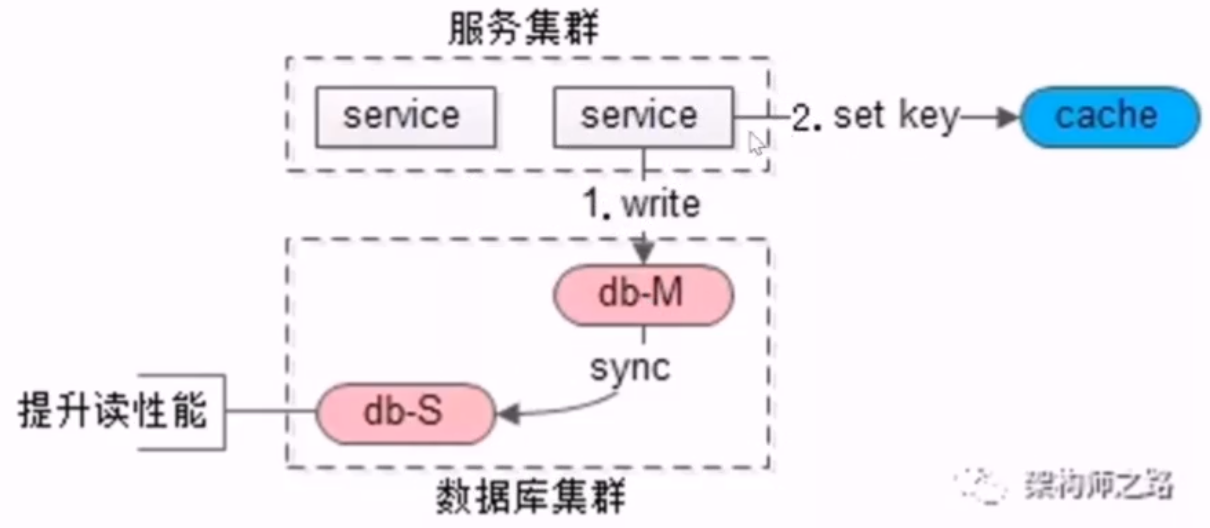
- 写完后,使用哪个库、哪个表、哪个主键拼接一个 key,设置到缓存里,并将这个 key 的时间记录为主从同步的时延
- 读操作过程
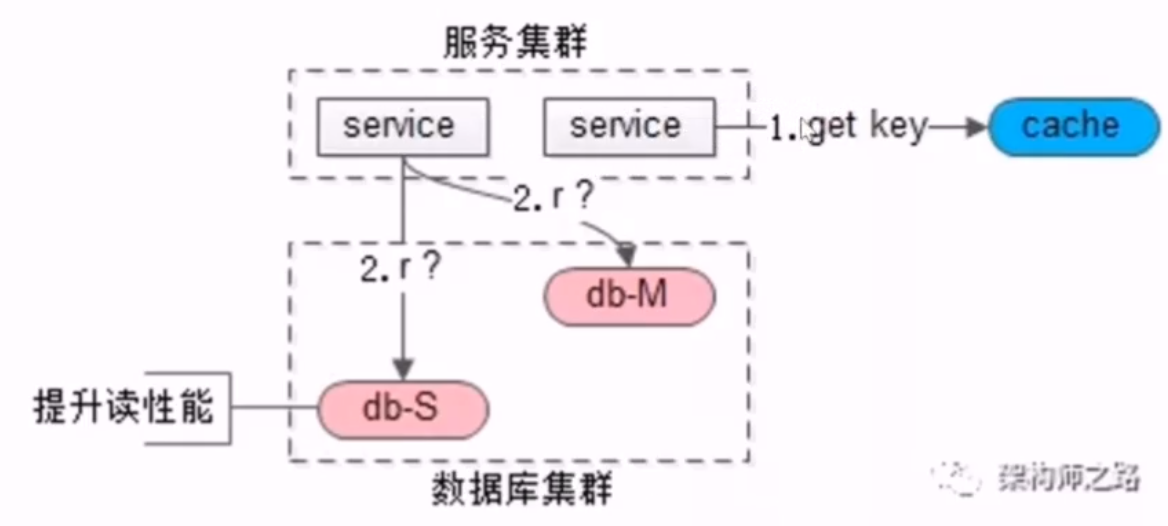
- 先读缓存,如果没有,再读从库
- 如果有,则读主库
- 写操作过程
- 方案一:忽略不计
- no23:主主数据冗余,为什么主主数据会不一致?
- 因为同时对外提供服务,并发的写入可能会造成数据同步失败,这个比主从的同步时延要严重,这个可能会造成数据丢失
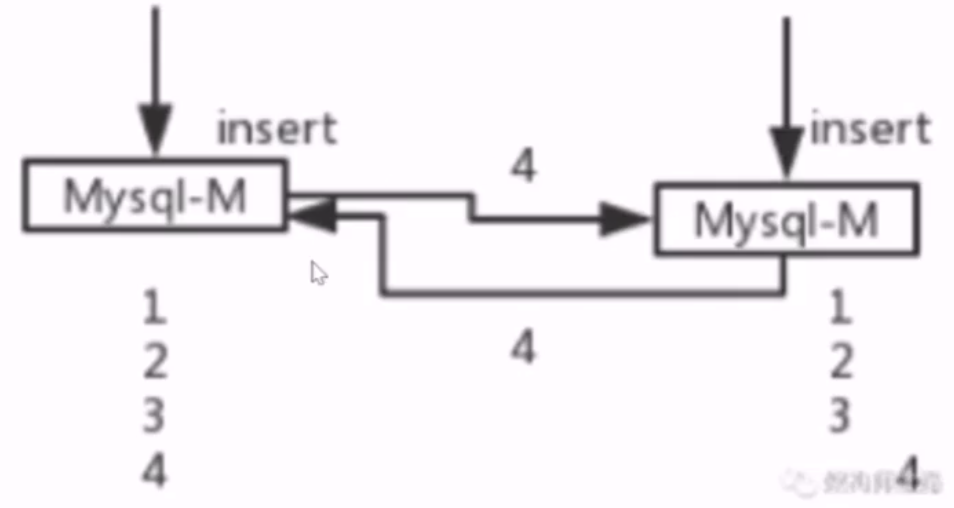
- no23:主主数据冗余,主主数据不一致的 3 种解决方案是什么?
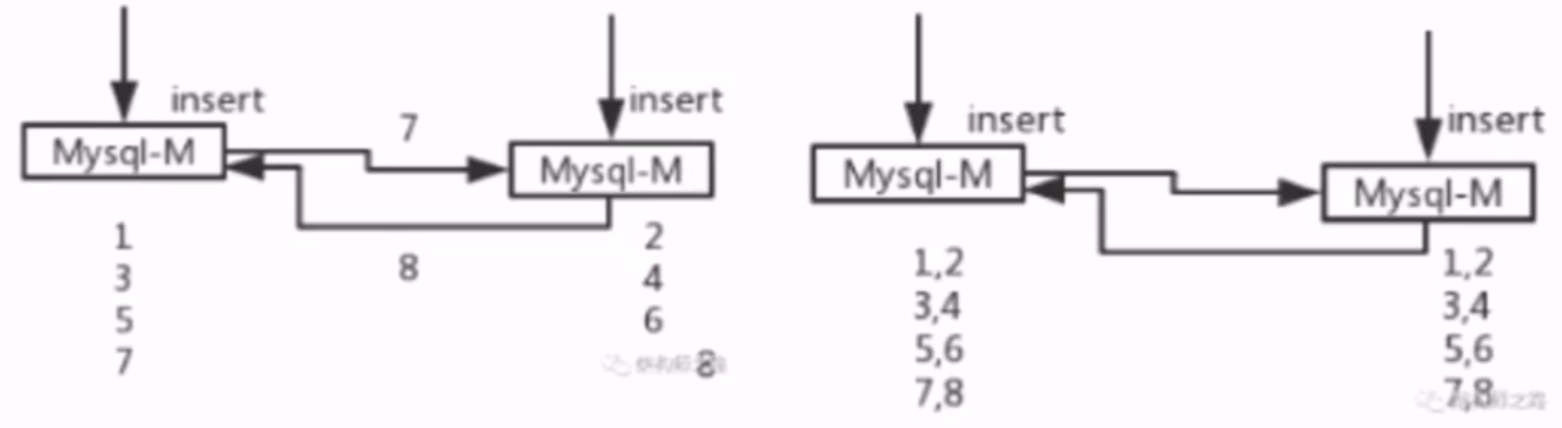
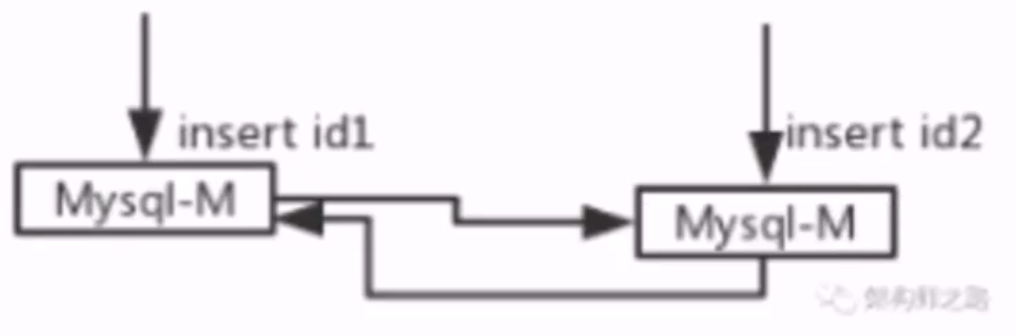
- 方案一:数据库层面解决,不同初始值,相同递增步长
- 方案二:数据库上层应用程序控制 id 生成
- 方案三:主主同时服务,升级为单主服务,影子主不服务
- 即keepalived+vip
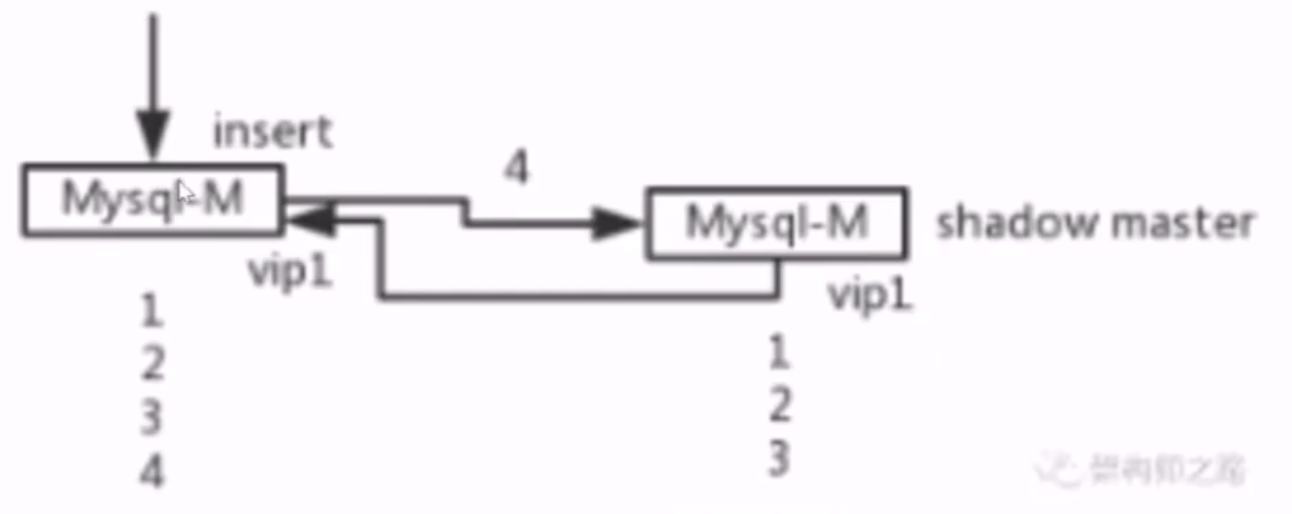
- 方案一:数据库层面解决,不同初始值,相同递增步长
24、数据库:扩展性,要如何解决?
- no24:数据库扩展性有哪些场景?
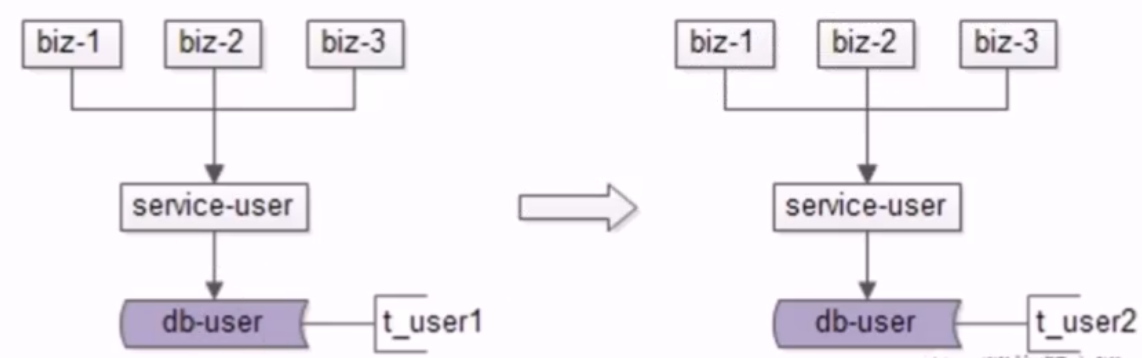
- 1.底层表结构变更
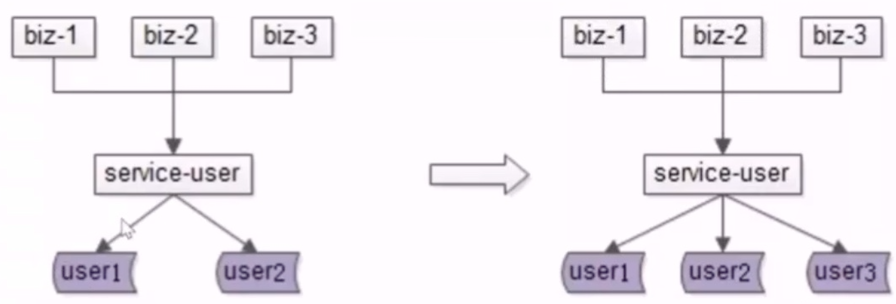
- 2.水平扩展,分库个数变化
- 3.底层存储介质变化
- 1.底层表结构变更
- no24:数据库进行扩展有哪五个方案?
- 1.停服扩展(离线,非高可用)
- 2.pt-online-schema-change(在线表结构变更)(平滑)
- 3.追日志方案(平滑)
- 4.双写方案(平滑)
- 5.秒级成倍扩容(平滑)
- no24:数据库扩展的停服扩展的步骤是怎样的?优缺点是什么?
- 步骤
- 1.挂公告
- 2.离线迁移数据
- 3.切到新库

- 优点
- 直观和简单
- 缺点
- 对服务的可用性有影响
- 必须在指定的时间完成升级,对技术人员压力非常大,一旦出现问题必须在规定时间内解决,否则只能回滚
- 步骤
- no24:数据库扩展的pt-online-schema-change(在线表结构变更)步骤、注意事项是什么?
- 步骤
- 1.创建一个扩展字段后的新表
- 2.在原表上创建三个触发器,对原表的所有写操作(insert、delete、update)都会对新表进行完全相同的操作
- 3.工具会分批地将原表中的数据分段地导入到新表
- 4.删除掉触发器,并将原表移走
- 5.将新建的新表重命名
- 整个过程不需要锁表,可以持续对外提供服务,rename 前是旧表,rename 前是新表
- 注意事项
- 1.变更过程中最重要的是处理冲突,原则是以触发器的最新数据为准,这要求被迁移的表必须有主键
- 2.在变更额度过程中,由于写操作要新建触发器,所以如果原表已有非常多的触发器,这个方案就不可行,但通常会禁用触发器
- 3.触发器的建立会影响原表的性能,这个操作必须在流量的低峰期进行
- 4.只适合 MySQL,也只适合表结构变更
- 步骤
- no24:数据库扩展的追日志方案的步骤是什么?
- 步骤
- 1.由旧库继续提供服务,并对服务进行一次升级,记录对旧库上的修改的日志,不需记录详细数据,只需记录哪个库哪个表哪个主键在什么时间被修改即可
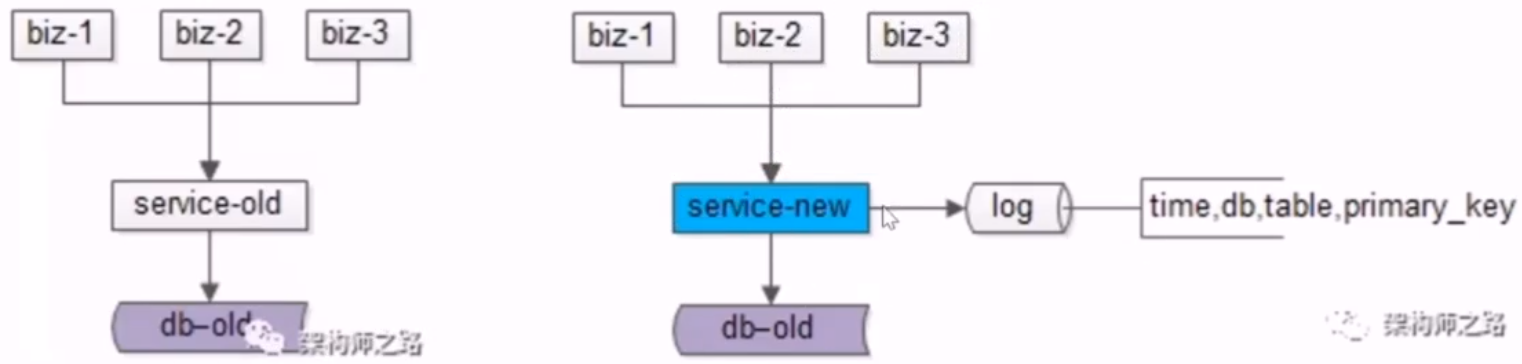
- 风险小,写接口的数量有限,改动点较少,升级过程增加了一些日志,对业务功能没有任何的影响
- 2.研发数据迁移工具,将数据从旧库迁移到新库
- 3.研发一个读取日志,看哪个库哪个表哪个主键发生了写操作,并将这些 key 从旧库再次覆盖到新库中,来对迁移数据过程里产生的数据差异进行追平,无论如何,当发生冲突时,以旧库中的数据为准,因为旧库的数据在实时更新
- 4.研发数据比对工具,将旧库和新库的数据进行比对,直到数据完全一致,才能修改配置迁库
- 5.迁移流量,对旧库进行一次秒级的 readonly,等日志重放程序完全追上之后,秒级的进行一个流量的切换
- 1.由旧库继续提供服务,并对服务进行一次升级,记录对旧库上的修改的日志,不需记录详细数据,只需记录哪个库哪个表哪个主键在什么时间被修改即可
- 步骤
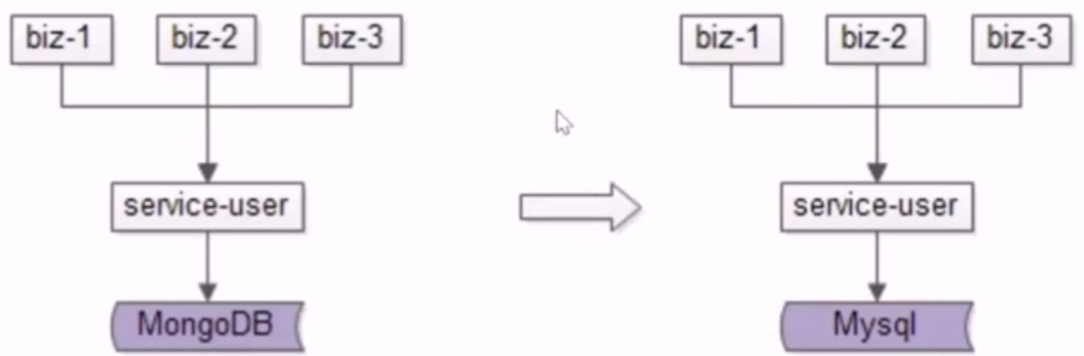
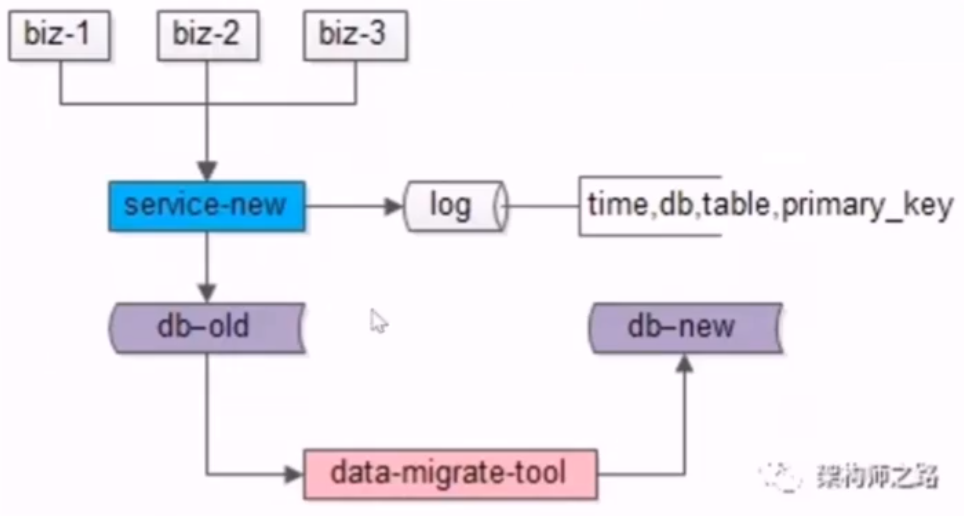
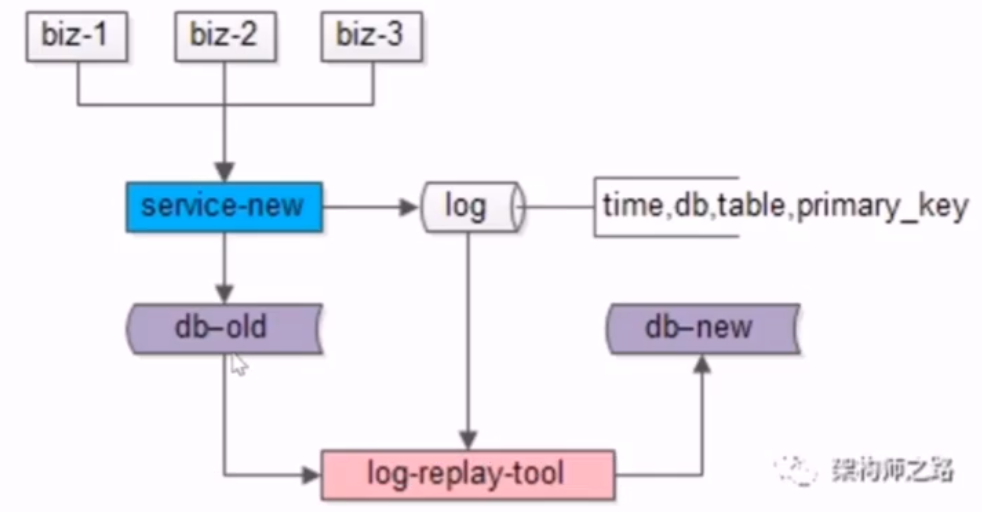
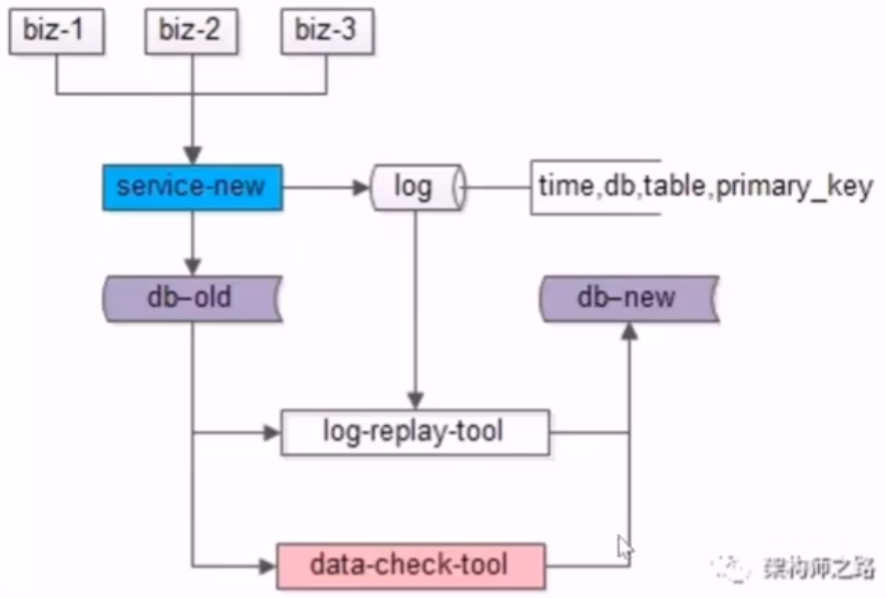

25、数据库:扩展性,平滑扩容方案?
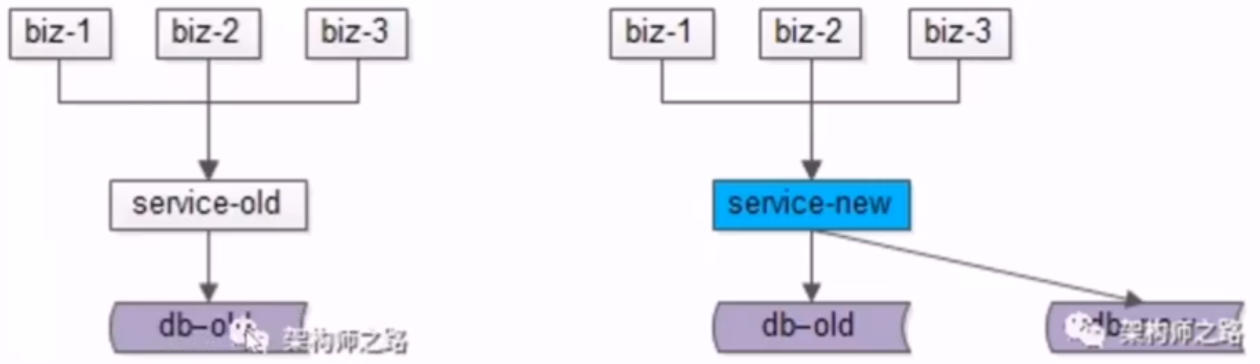
- no25:数据库平滑迁移的双写方案的 4 个步骤
- 1.首先旧库提供服务,先对服务进行升级,对数据修改写接口,并在新库上进行相同的操作
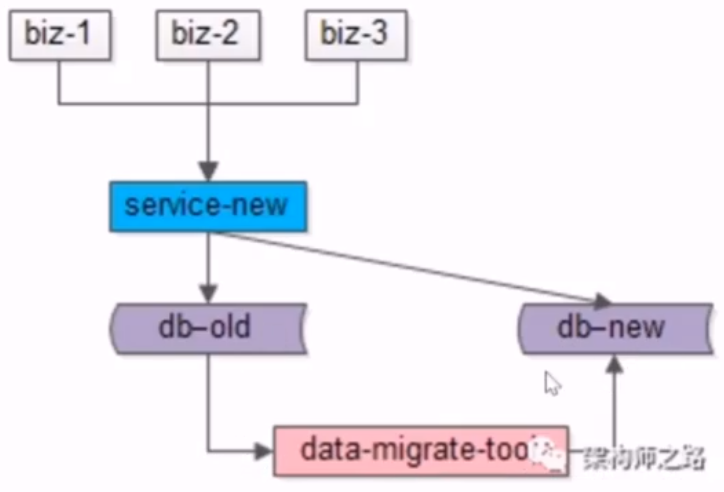
- 2.研发数据迁移工具,对数据进行迁移
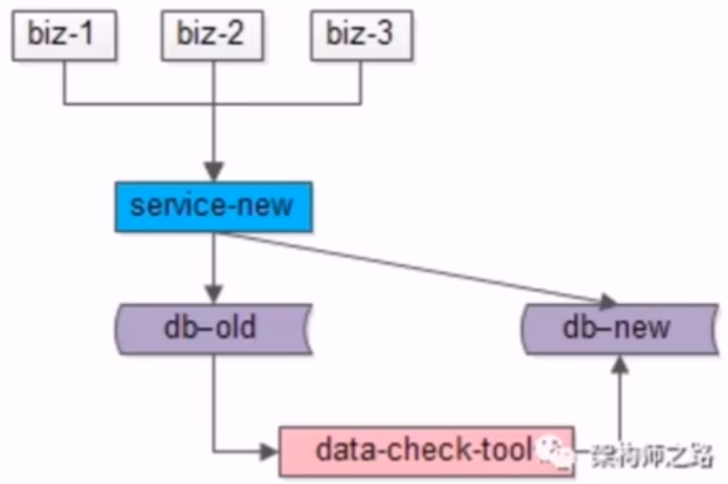
- 3.数据比对
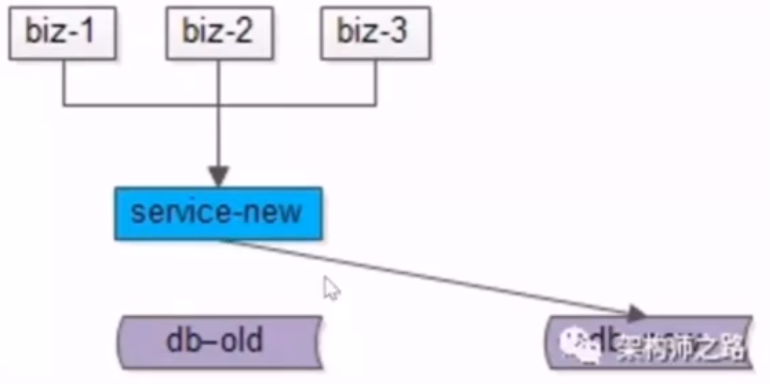
- 4.流量迁移
- 1.首先旧库提供服务,先对服务进行升级,对数据修改写接口,并在新库上进行相同的操作
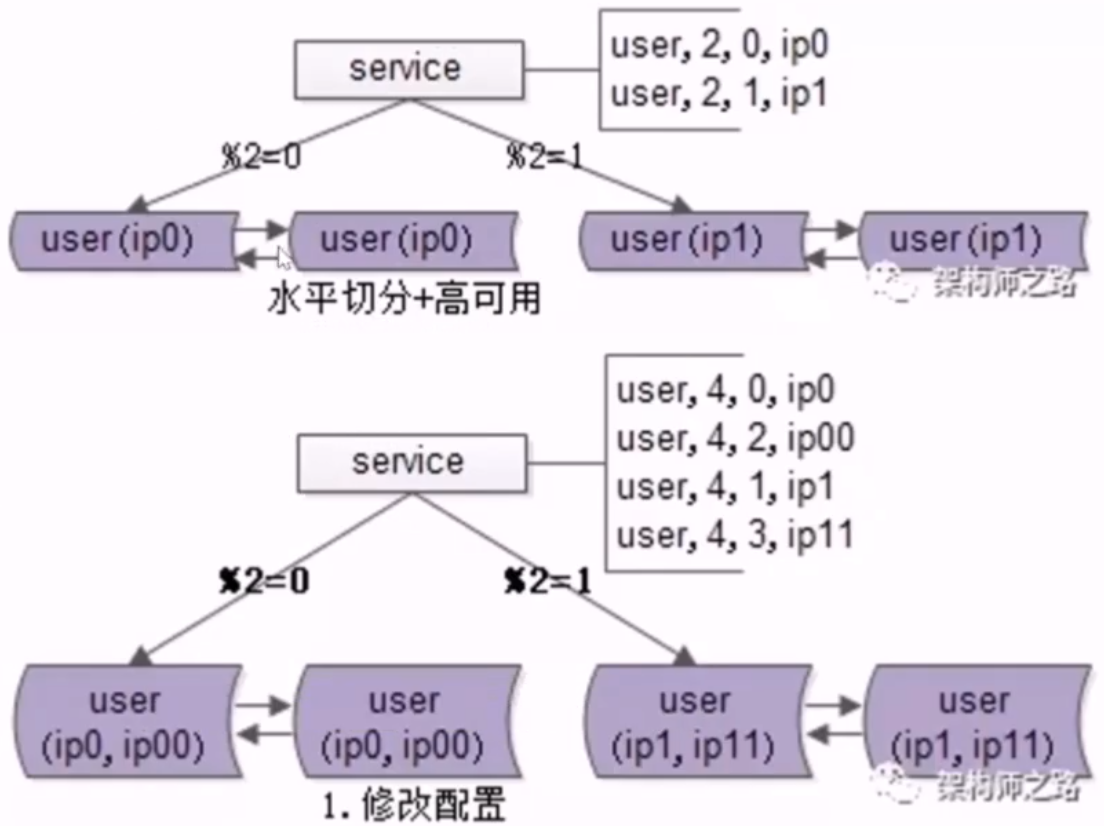
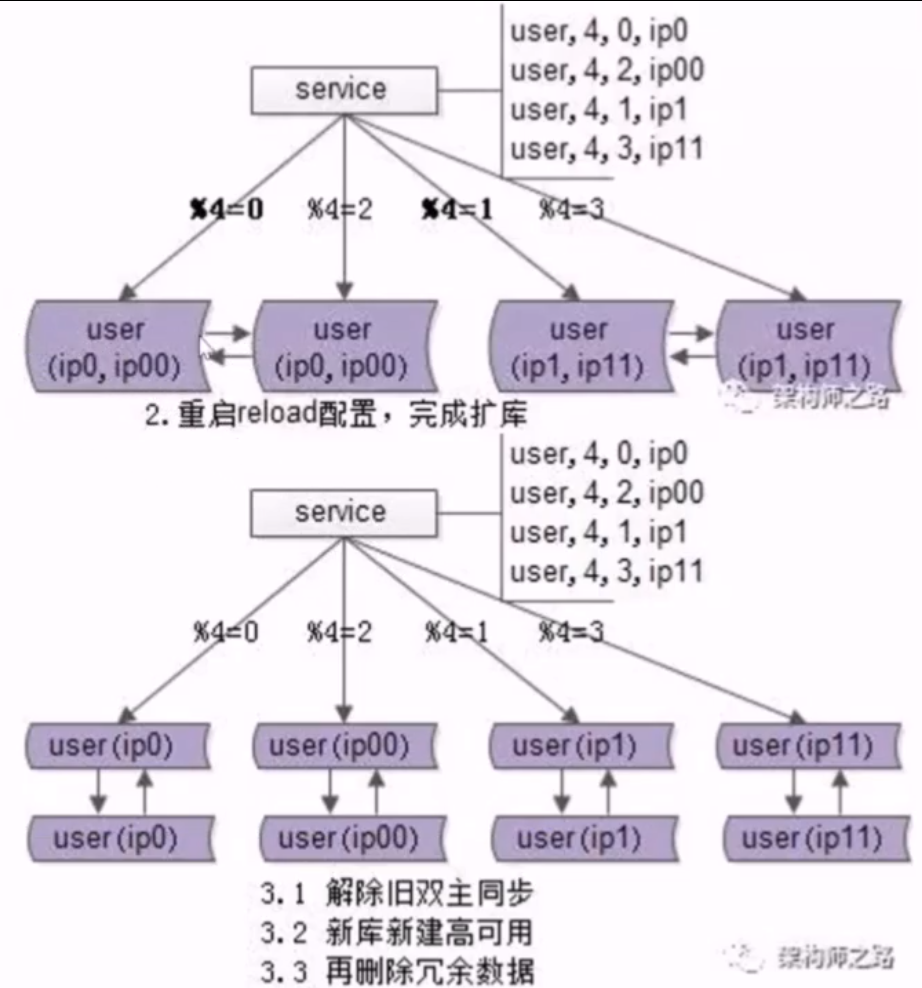
26、数据库:水平切分,数据库秒级扩容!
- no26:数据库水平切分,秒级成倍扩容的 3 个步骤
- 前提条件
- 实施了微服务的分层架构,大数据量进行了水平切分,高可用做了 keepalived 加 vip
- 步骤
- 1.修改配置(双虚 IP,微服务数据库路由)
- 2.服务层 reload 配置,实例增倍完成
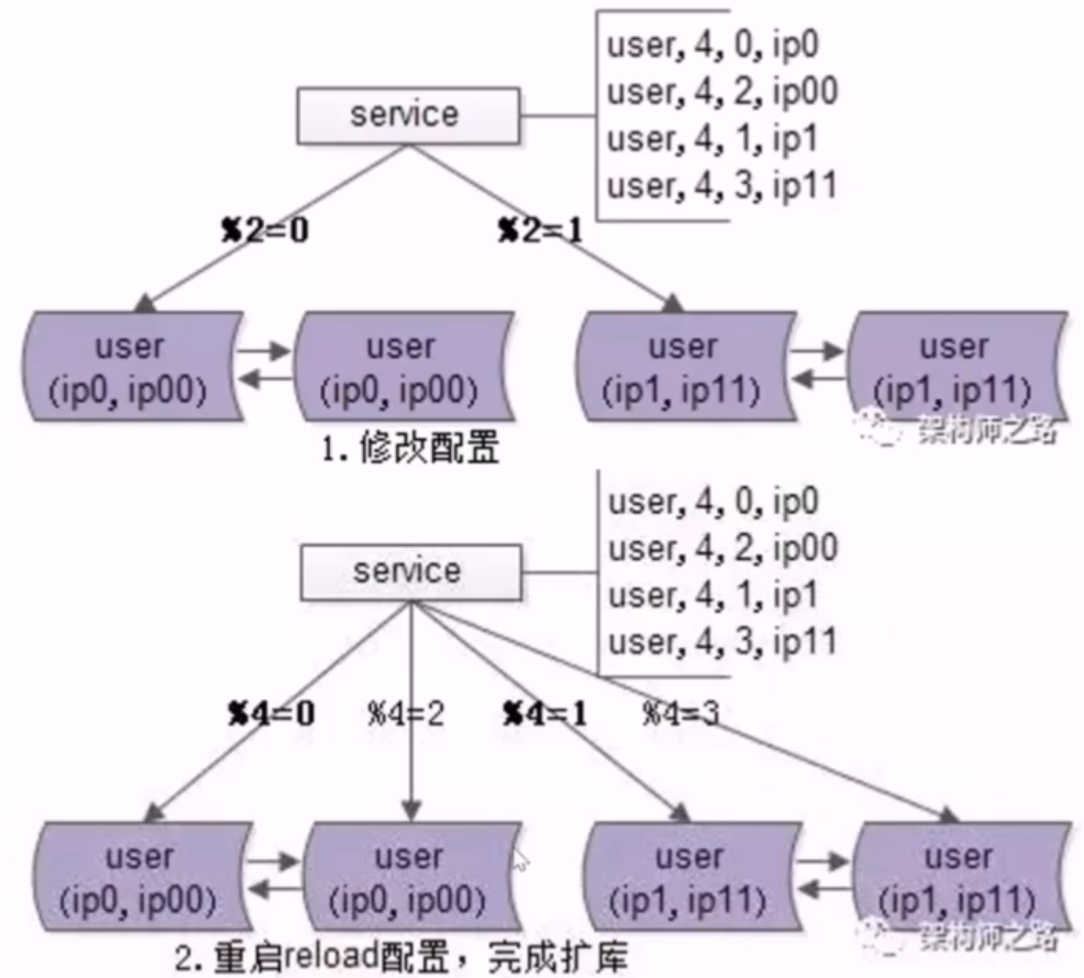
- reload 配置方案
- 1.重启服务,读新文件
- 2.配置中心给服务层发信号,重新读取配置文件
- 3.收尾:解除旧双主同步,新增新的双主同步,删除冗余数据,数据量减半完成
- 1.修改配置(双虚 IP,微服务数据库路由)
- 前提条件