Replicated State Machine(复制状态机) 和 Primary-Backup System 的对比
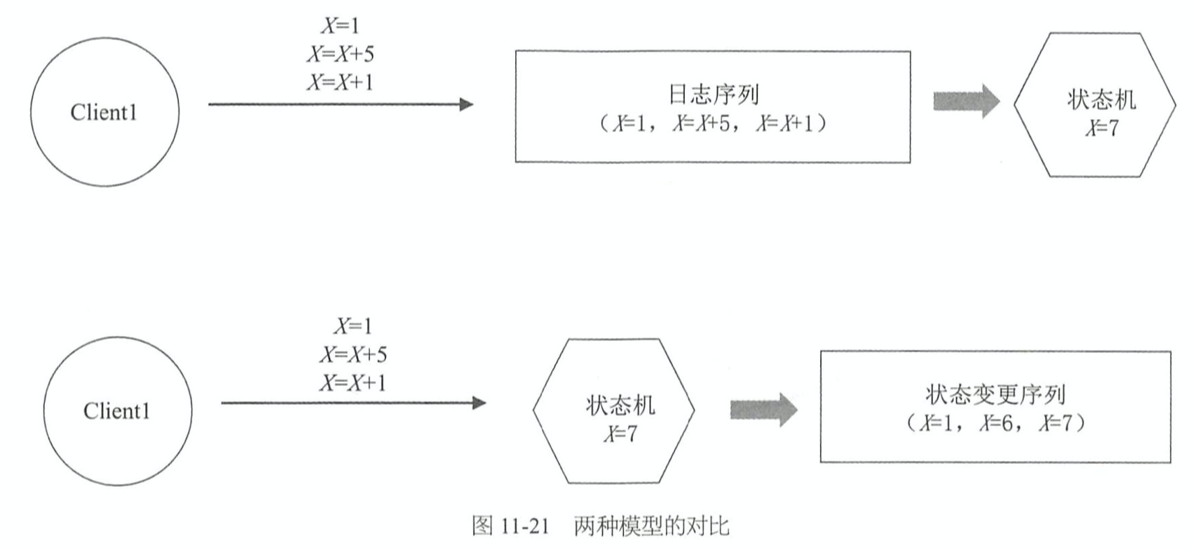
- 假设初始时 X=0,客户端发送了 X=1, X=X+5,X=X+1 三个指令
- Replicated State Machine(复制状态机)
- 节点持久化的是日志序列,在节点之间复制的是日志序列,然后把日志序列应用到状态机(X),最终 X=7
- Primary-Backup System
- 节点存储和复制的都是 X=1、X=6、X=7 这种状态的变化序列
- 两种模型的对比
- 1.数据同步次数不一样
- 存储的是日志序列:客户端的所有写请求都要在节点之间同步,不管状态有无变化
- 存储的是状态变化:只需同步最后一条数据
- 2.存储状态变化
- 以客户端发送一个指令 X = X+1 为例
- 日志序列:Apply 多次就会出现问题
- 状态变化:具有幂等性,如 X=6,Apply 多次也没关系
Primary-Backup 复制模型在 ZAB 中的应用
- Zookeeper 是一个树状结构,ZAB 是单点写入,客户端的写请求都会写入Primary Node,Primary Node更新自己本地的树,这棵树也就是上面所说的状态机,完全在内存当中,对应的树的变化存储在磁盘上面,称为Transaction日志。Primary节点把Transaction日志复制到多数派的Backup Node上面,BackupNode根据Transaction日志更新各自内存中的这棵树
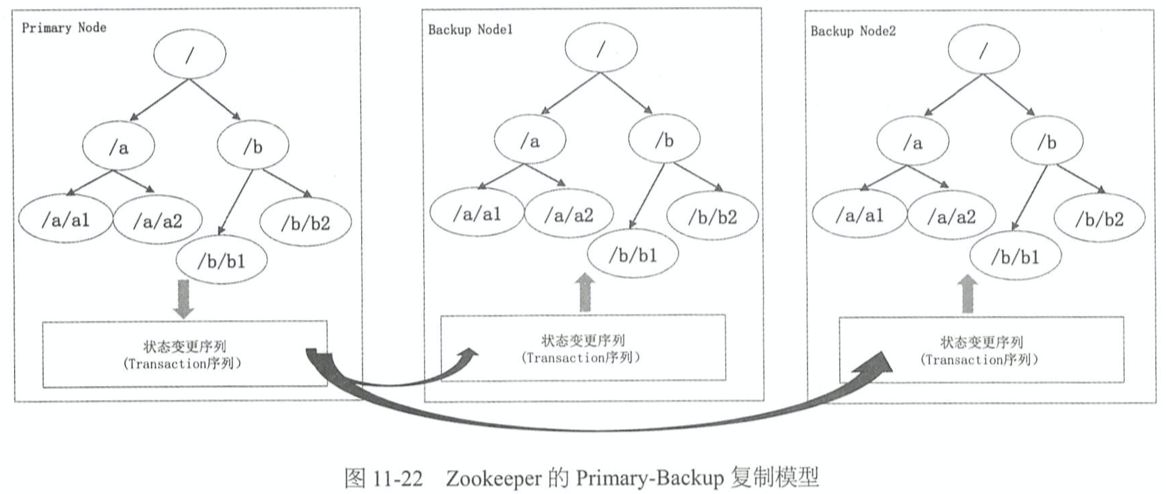
zxid 的原理
- Zookeeper中的Transaction指的并不是客户端的请求日志,而是Zookeeper的这棵内存树的变化。每一次客户端的写请求导致的内存树的变化,生成一个对应的Transaction, 每个Transaction有一个唯一的 ID,称为zxid
- 在Raft里面,每条日志都有一个term和index,把这两个拼在一起,就类似于zxid。 zxid 是一个64位的整数,高32位表示Leader的任期,在Raft里面叫term,这里叫epoch;低32位是任期内日志的顺序编号
- 对于每一个新的epoch, zxid 的低32位的编号都从0开始。这是不同于Raft的一个地方,在Raft里面,日志的编号呈全局的顺序递增。
- 两条日志的新旧比较办法和Raft中两条日志的比较办法类似:
- 1.日志a的epoch大于b的epoch, 则日志a的zxid大于b的zxid, 日志a比日志b新
- 2.日志a的epoch等于b的epoch,并且日志a的编号大于日志b的编号,则日志a的zxid大于b的zxid,日志a比日志b新
ZAB 是如何保证日志的顺序提交的
- 因为 Raft 和 ZAB 使用了单点写入,Paxos 则不能保证,因为是多点写入,乱序提交
- 这样日志有了「时序」的保证,就相当于在全局为每条日志做了个顺序的编号!基于这个编号,就可以做日志的顺序提交、不同节点间的日志比对,回放日志的时候,也可以按照编号从小到大回放
- 基于「序」的本质概念,可以保证以下几点
- 1.如果日志a小于日志b,则所有节点一定先广播a,后广播b
- 2.如果日志a小于日志b,则所有节点一定先Commit a, 后Commit b。这里的Commit,指的是Apply到状态机。
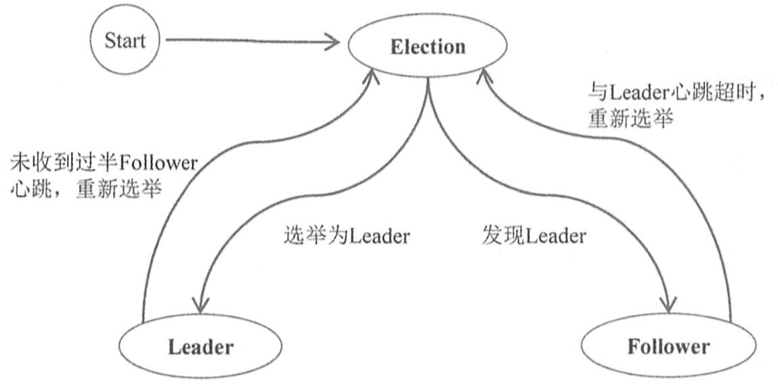
ZAB算法选举时,集群有哪4种角色?
- Leader: 主节点
- Follower: 跟随者节点
- Observer: 观察者,无投票权
- Election:类似 Raft 的 Candidate 状态,即自己进入选举状态
ZAB算法选举过程中,集群中的节点拥有哪4个状态?
- Looking/Election(选举)状态:当节点处于该状态时,它会认为当前集群中没有Leader,因此自己进入选举状态
- Leading(领导者)状态:表示已经选出主,且当前节点为Leader
- Following(跟随者)状态:集群中已经选出主后,其它非主节点状态更新为Following,表示对Leader的追随
- Observing(观察者)状态:表示当前节点为Observer,持观望态度,没有投票权和选举权
ZAB算法的节点的数据结构三元组(server_id, server_zxID, epoch)分别是什么意思?
- server_id: 本节点的唯一ID
- server_zxID: 本节点存放的数据ID,数据ID越大表示数据越新,选举权重越大
- epoch: 当前选取轮数,一般用逻辑时钟表示
ZAB算法的核心和选主原则是什么?
- 核心:少数服从多数,ID大的节点优先成为主
- 选主原则:server_zxID最大者成为Leader, 若server_zxID相同,则server_id最大者成为Leader
Zookeeper 实现 ZAB 的 3 个阶段
Leader 选举:FLE(Fast Leader Election)算法
- 在初始的时候,节点处于Election 状态,然后开始发起选举,选举结束,处于Leader或者Follower状态
- 在Raft里面,Leader 和Follower之间是单向心跳,只会是Leader给Follower 发送心跳。但在Zab里面是双向心跳,Follower 收不到Leader的心跳,就切换到Election状态发起选举;反过来,Leader 收不到超过半数的Follower心跳,也切换到Election 状态,重新发起选举
- Raft 选取日志最新的节点作为新的 Leader
- ZAB 选取zxid 最大的节点作为 Leader,如果所有的节点的 zxid 相等,如系统刚初始化的时候,所有节点的 zxid 都为 0,此时将选取节点编号最大的节点作为Leader(Zookeeper为每个节点配置了一个编号)
正常阶段:2 阶段提交
- 接收客户端的请求,然后复制到多数派,在 Zookeeper 里面也成为 2 阶段提交
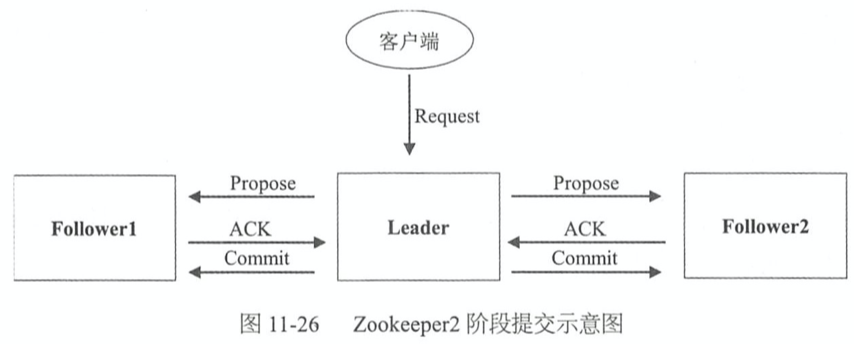
- 阶段1:Leader收到客户端的请求,先发送Propose消息给所有的Follower,收到超过半数的Follower返回的ACK消息
- 阶段2:给所有节点发送Commit消息
- 注:
- 1.Commit是纯内存操作。这里所说的Commit指的是Raft里面的Apply,Apply到Zookeeper的状态机
- 2.在阶段1,收到多数派的ACK后,就表示返回给客户端成功了。而不是等多数派的节点收到Commit,再返回给客户端
- 3.Propose 阶段有一次落盘操作,也就是生成一条Transaction日志,落盘。这与MySQL中Write-ahead Log原理类似
恢复阶段:当 Leader 宕机后,新选出了 Leader,其它 Follower 要切换到新的 Leader,从新的 Leader 同步数据
- Raft 里面的恢复阶段是,新选出的 Leader 发出一个空的 AppendEntries RPC 请求,即复用了正常复制阶段的通信协议
- 在 ZAB 里面是,Leader 日志不动,Follower 要与 Leader 做日志比对,然后可能做日志的截断、补齐等操作
- 恢复的算法和Raft的AppendEntries 很类似,只是在Raft里面这些工作都由Follower自己做了。而在这里,是Leader把主要的工作做了,Leader 比对日志,然后告诉Follower做截断、补齐或全量同步
ZAB算法的选举过程是怎样?
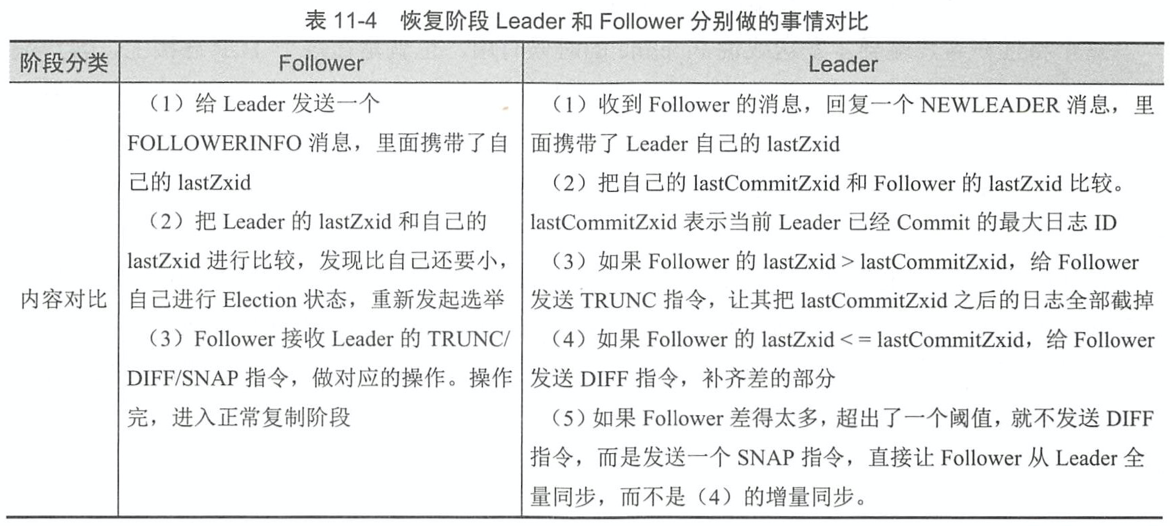
- 1.当系统刚启动时,3个服务器当前投票均为第一轮投票,即epoch=1, 且zxID均为0。此时每个服务器都推选自己,并将选票信息<epoch, vote_id, vote_zxID>广播出去
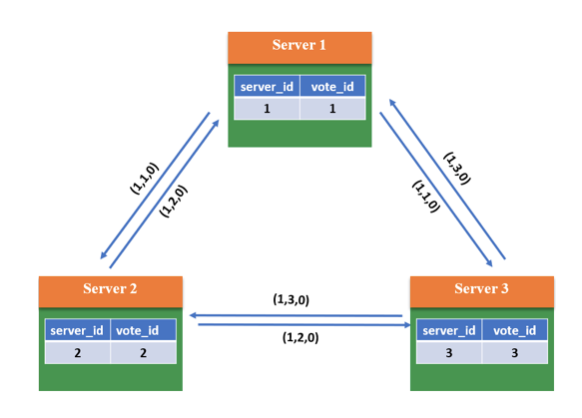
- 2.根据判断规则,由于3个Server的epoch、zxID都相同,因此比较server_id,较大者即为推选对象,因此Server1和Server2将vote_id改为3,更新自己的投票箱并重新广播自己的投票
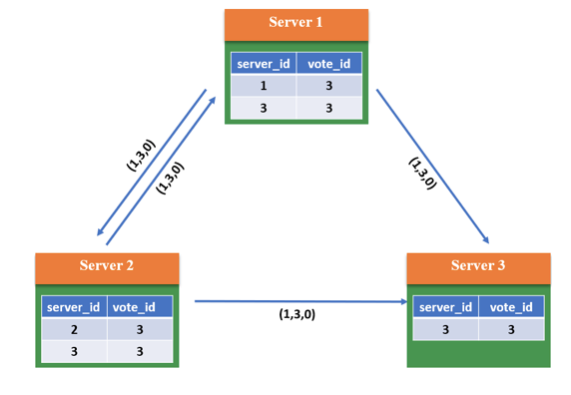
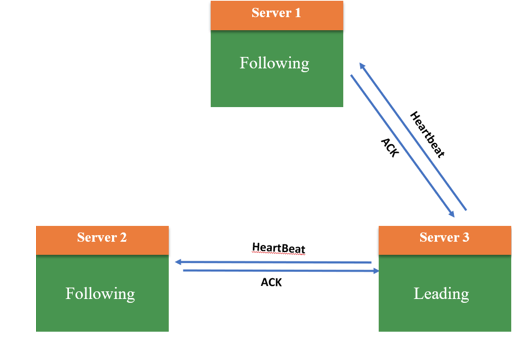
- 3.此时系统内所有服务器都推选了Server3,因此Server3当选Leader,处于Leading状态,向其它服务器发送心跳包并维护连接;Server1和2处于Following状态
优点
- 1.性能高,对系统无特殊要求
- 2.选举稳定性比较好,当有新节点加入或节点故障恢复后,会触发选主,但不一定会真正切主,除非新节点或故障后恢复的节点数据 ID 和节点 ID 最大,且获得投票数过半,才会导致切主
缺点
- 1.采用广播方式发送信息,若节点中有n个节点,每个节点同时广播,则集群中信息量为n*(n-1)个消息,容易出现广播风暴
- 2.除了投票,还增加了对比节点ID和数据ID,这就意味着还需要知道所有节点ID和数据ID,所以选举时间相对较长
参考
- 分布式协议与算法实战-极客时间
- 分布式技术原理与算法解析-极客时间
- 软件架构设计 大型网站技术架构与业务架构融合之道
