
05 | Paxos算法(一):如何在多个节点间确定某变量的值?
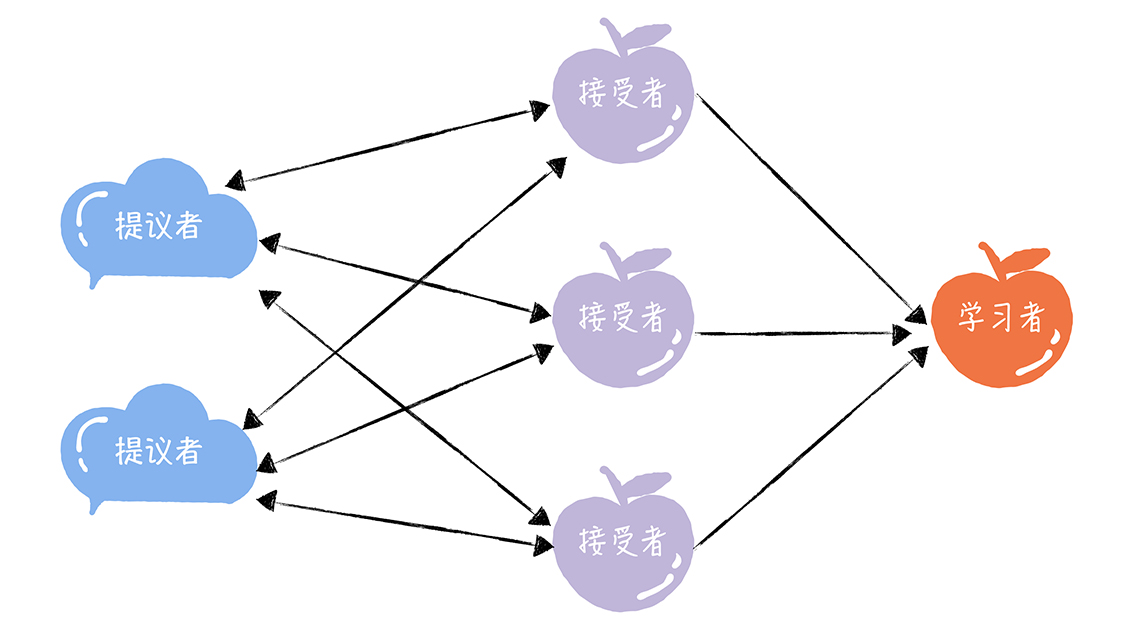
- Q:Basic Paxos的三种角色
- 提议者(Proposer):提议一个值用于投票表决,可把客户端当成提议者。但在绝大多数场景中,集群中收到客户端请求的节点,才是提议者。好处是对业务代码没有入侵性,即不需要再业务代码中实现算法逻辑,可像使用数据库一样访问后端数据。代表的是接入和协调功能,收到客户端请求后,发起二阶段提交,进行共识协商
- 接受者(Acceptor):对每个提议的值进行投票,并存储接受的值。一般集群中的所有节点都在扮演接受者的角色,参与共识协商,并接受和存储数据。代表投票协商和存储数据,对提议的值进行投票,并接受达成共识的值,存储保存
- 学习者(Learner):被告知投票的结果,接受达成共识的值,存储保存,不参与投票的过程。通常学习者是数据备份节点,如「Master-Slaev」模型中的Slave,被动地接受数据,容灾备份。代表存储数据,不参与共识协商,值接受达成共识的值,存储保存
- Q:Basic Paxos如何达成共识
- 假设客户端 1 的提案编号为 1,客户端 2 的提案编号为 5,并假设节点 A、B 先收到来自客户端 1 的准备请求,节点 C 先收到来自客户端 2 的准备请求
- 准备(Prepare)阶段
- 客户端1、2作为提议者,分别向所有接受者发送包含提案编号的准备请求
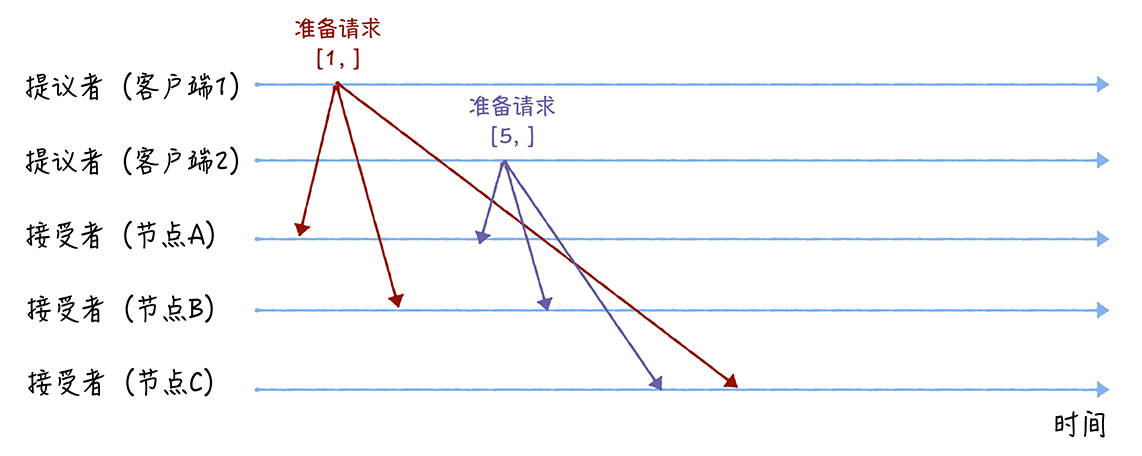
- 在准备请求中是不需要指定提议的值的,只需要携带提案编号即可
- 当节点A、B收到提案编号为1的准备请求,节点C收到提案编号为5的准备请求后,将这样处理:
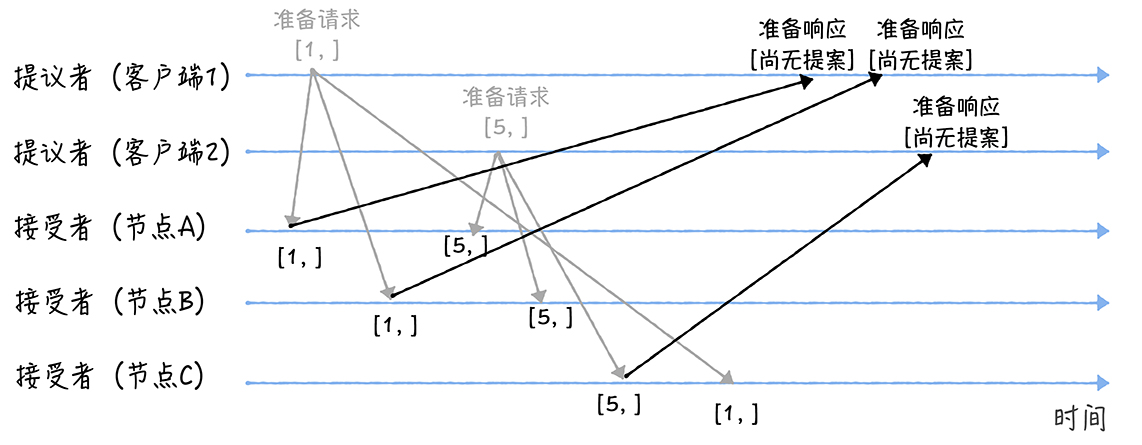
- 由于之前没有通过任何提案,所以结点A、B将返回一个「尚无提案」的相应,并以后不再响应提案编号小于等于1的准备请求,不会通过编号小于1的提案
- 结点C则返回「尚无提案」的响应并以后不再响应提案编号小于等于5的准备请求,不会通过编号小于5的提案
- 另外,当节点 A、B 收到提案编号为 5 的准备请求,和节点 C 收到提案编号为 1 的准备请求的时候,将这样处理:
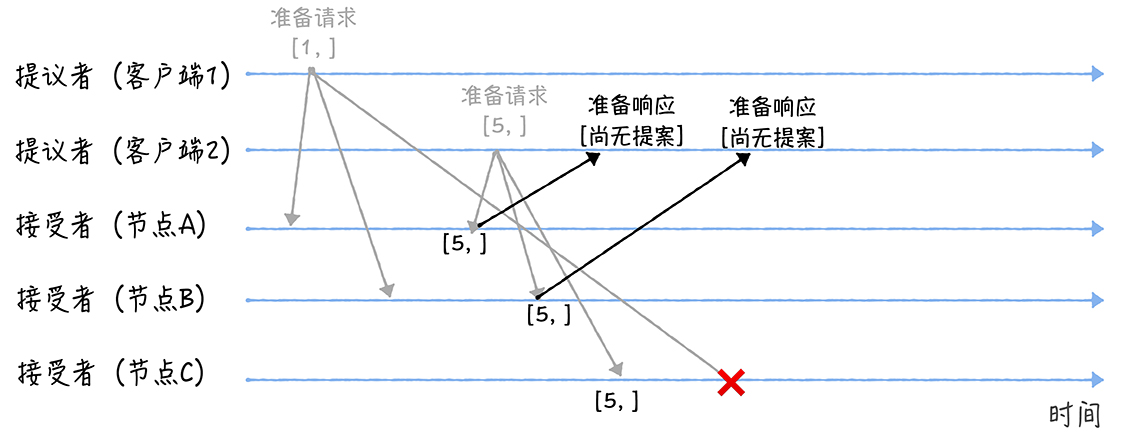
- 当节点A、B收到提案编号为5的准备请求的时候,因为提案编号5大于它们之前响应的准备请求的提案编号1,而且两个节点都没有通过诺任何提案,所以它将返回一个「尚无提案」的响应,并承诺以后不再响应提案编号小于等于5的准备请求,不会通过编号小于5的提案
- 当节点C收到提案编号为1的准备请求的时候,由于提案编号1小于它之前响应的准备请求的提案编号5,所以丢弃该准备请求,不做响应
- 接受(Accept)阶段
- 首先客户端1、2在收到大多数节点的准备响应之后,会分别发送接受请求:
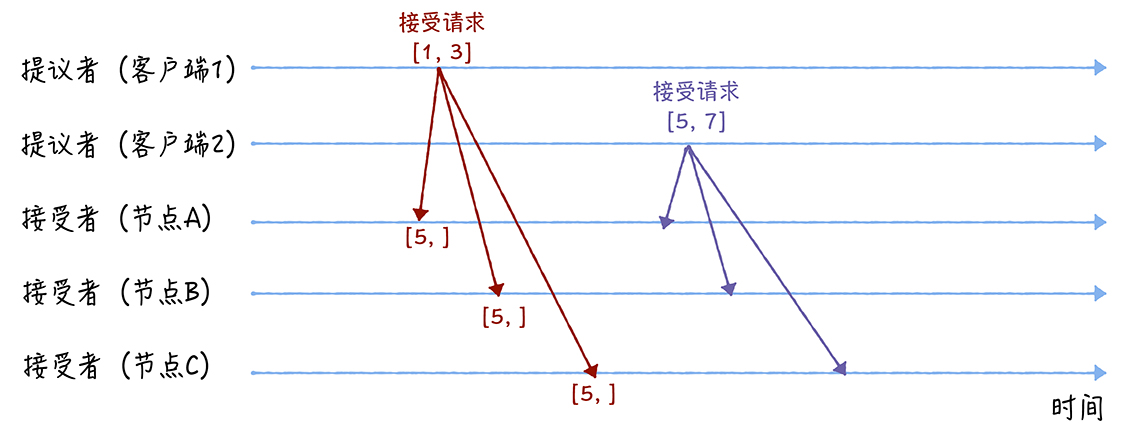
- 当客户端1收到大多数的接受者(节点A、B)的准备响应后,根据响应中提案编号最大的提案的值,设置接受请求中的值。因为该值在来自节点A、B的准备响应中都为空,所以就把自己的提议值3作为提案的值,发送接受请求[1, 3]
- 当客户端2收到大多数的接受者的准备响应后(节点A、B和节点C),根据响应中提案编号最大的提案的值,来设置接受请求中的值。因为该值来自节点A、B、C的准备响应中都为空,所以就把自己的提议值7作为提案的值,发送请求[5, 7]
- 当三个节点收到2 个客户端的接受请求时,会这样处理:
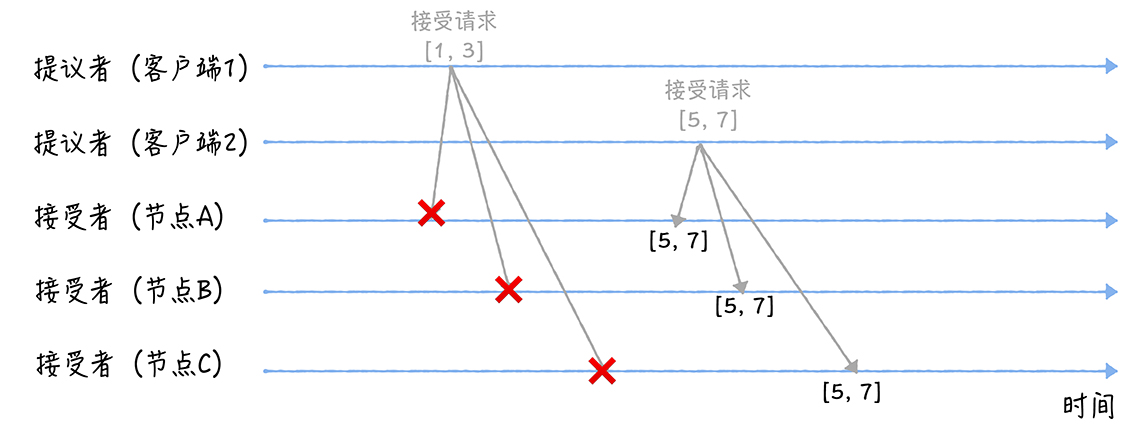
- 当节点A、B、C收到接受请求[1, 3]时,由于提案的提案编号1小于三个节点承诺能通过的提案的最小提案编号5,所以提案[1, 3]将被拒绝
- 当节点A、B、C收到接受请求[5, 7]的时候,由于提案的提案编号 5 不小于三个节点承诺能通过的提案的最小提案编号 5,所以就通过提案[5, 7],也就是接受了值 7,三个节点就 X 值为 7 达成了共识
- 如果集群中有学习者,当接受者通过了一个提案时,就通知给所有的学习者。当学习者发现大多数的接受者都通过了某个提案,那么它也通过该提案,接受该提案的值
- Basic Paxos的容错能力,源自「大多数」的约定,即当少于一半的节点出现故障的时候,共识协商仍然在正常工作
- 本质上而言,提案编号的大小代表着优先级,根据提案编号的大小, 接受者保证三个承诺
- 如果准备请求的提案编号,小于等于接受者已经响应的准备请求的提案编号,那么接受者将承诺不响应这个准备请求
- 如果接受请求中的提案的提案编号,小于接受者已经响应的准备请求的提案编号,那么接受者将承诺不通过这个提案
- 如果接受者之前有通过提案,那么接受者将承诺,会在准备请求的响应中,包含已经通过的最大编号的提案信息
07 | Raft算法(一):如何选举领导者?
- Q:Raft算法的成员身份(服务器节点状态)
- 领导者(Leader):主要工作有处理写请求、管理日志复制和不断地发送心跳信息
- 跟随者(Follower):默默接收和处理来自领导者的消息,当等待领导者心跳信息超时的时候,主动站出来,推荐自己当候选人
- 候选人(Candidate):候选人将向其它节点发送请求投票(RequestVote) RPC消息,通知其它节点来投票,如果赢得了大多数选票,就晋升当领导者
- Raft算法是强领导者模型,集群中只能有一个领导者
- Q:Raft算法选举领导者的过程
- 在初始状态下,集群中所有的节点都是跟随者的状态
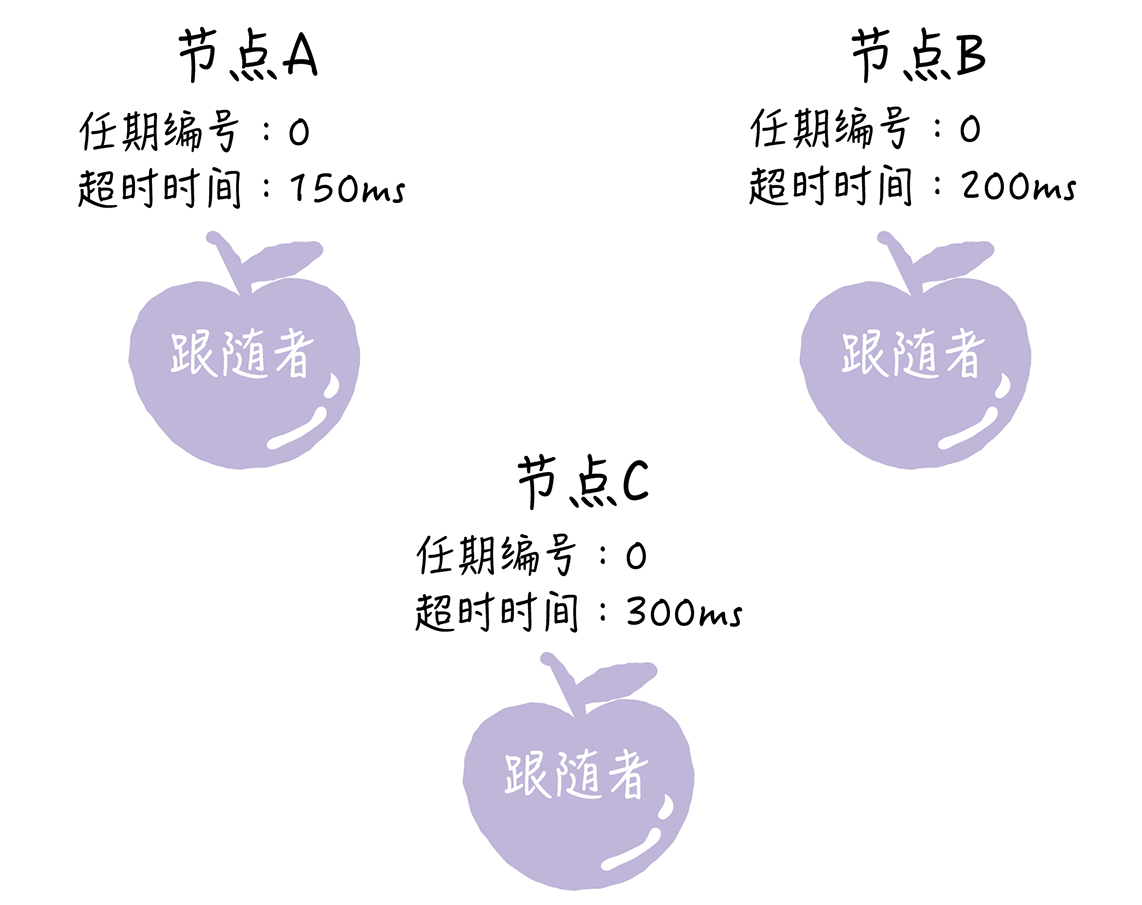
- Raft算法实现了随机超时时间的特性,即每个节点等待领导者节点心跳信息的超时时间间隔是随机的。如上图,集群中没有领导者,而节点A的等待超时时间最小(150ms),它会最先因为没有等到领导者的心跳信息,发生超时
- 这时,节点A就增加自己的任期编号,推举自己为候选人,先给自己投上一张选票,然后向其他节点发送请求投票 RPC 消息,请它们选举自己为领导者
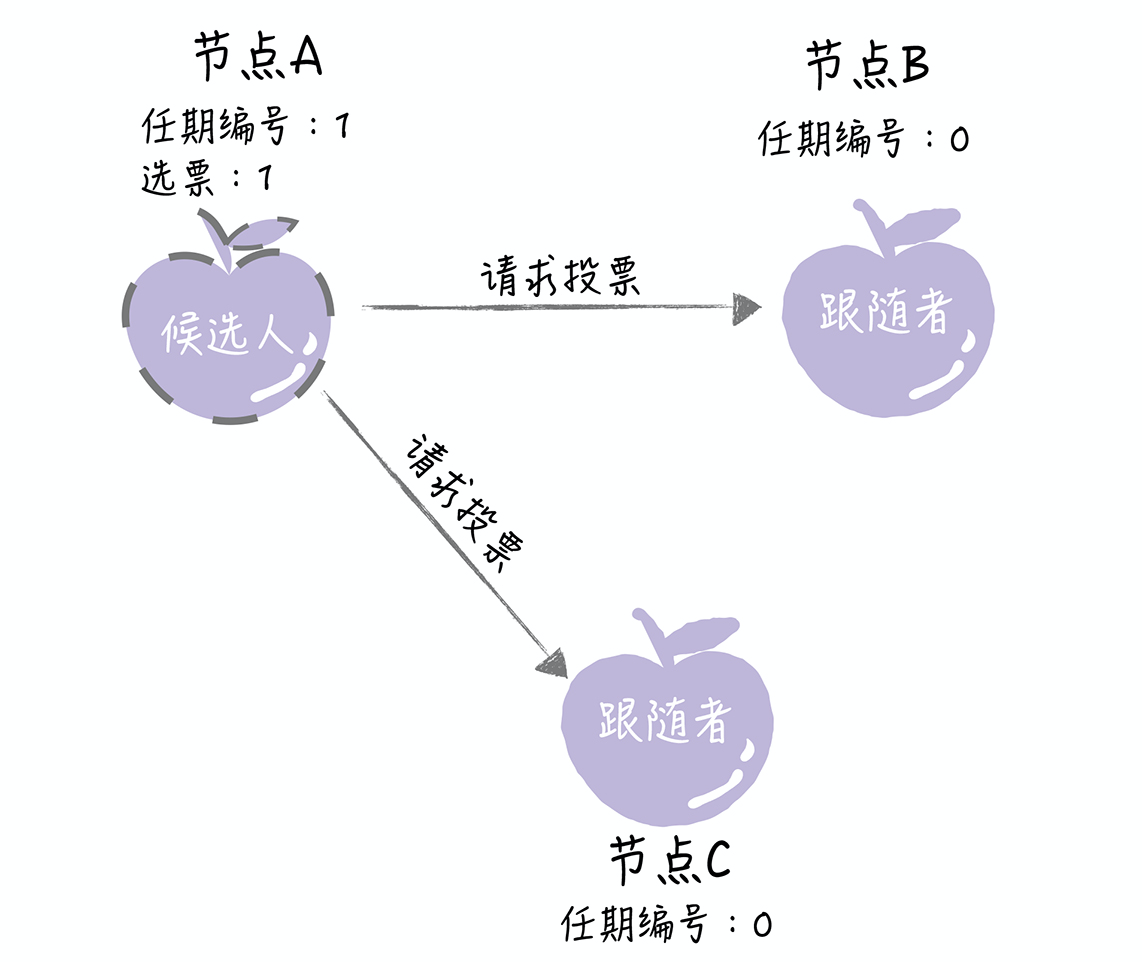
- 如果其它节点接收到候选人A的请求投票RPC消息,在编号为1的这届任期内,也还没有进行过投票,那么它将把选票投给节点A,并增加自己的任期编号
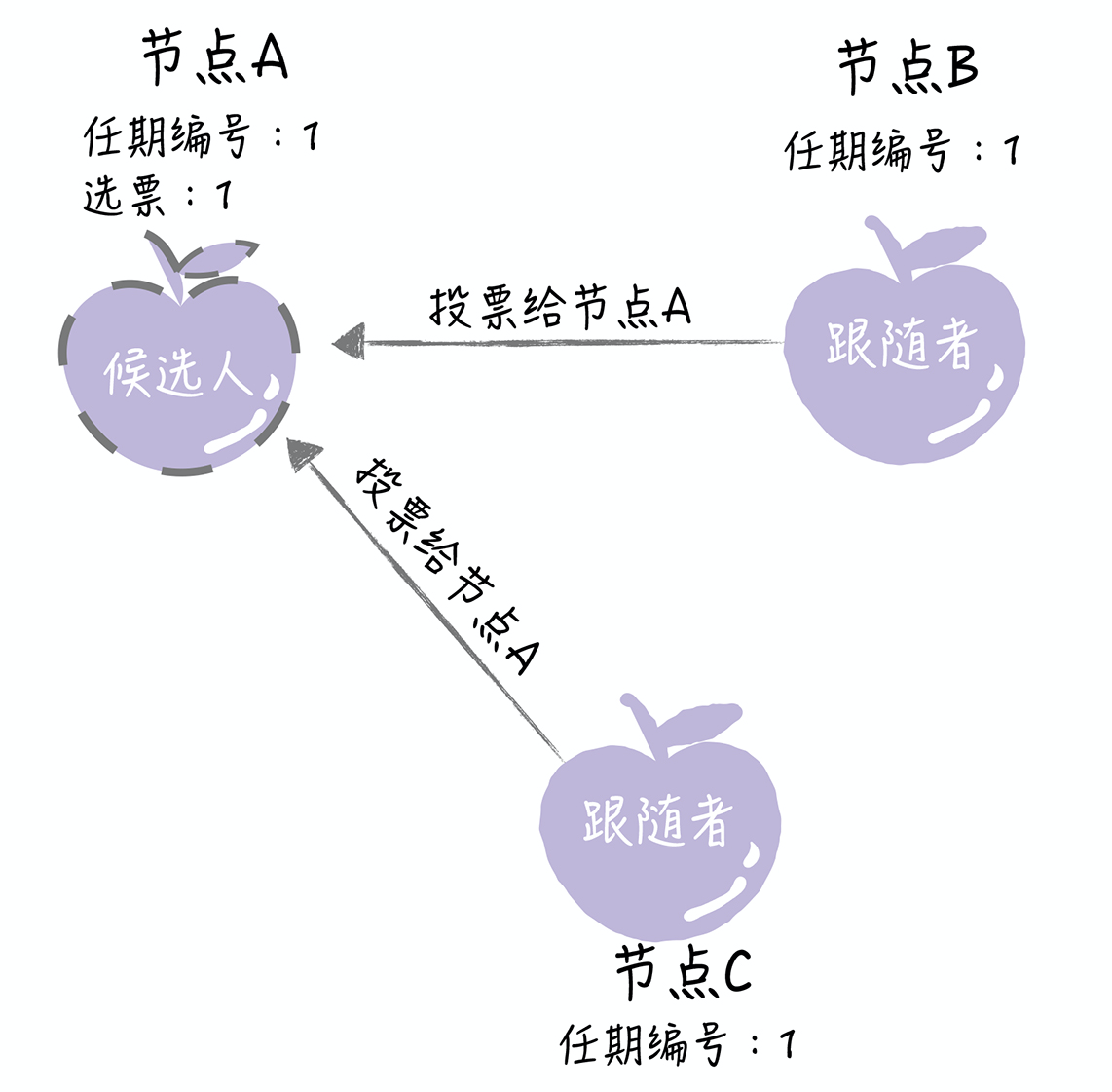
- 如果候选人在选举超时时间内赢得了大多数的选票,那么它就会成为本届任期内的新领导者
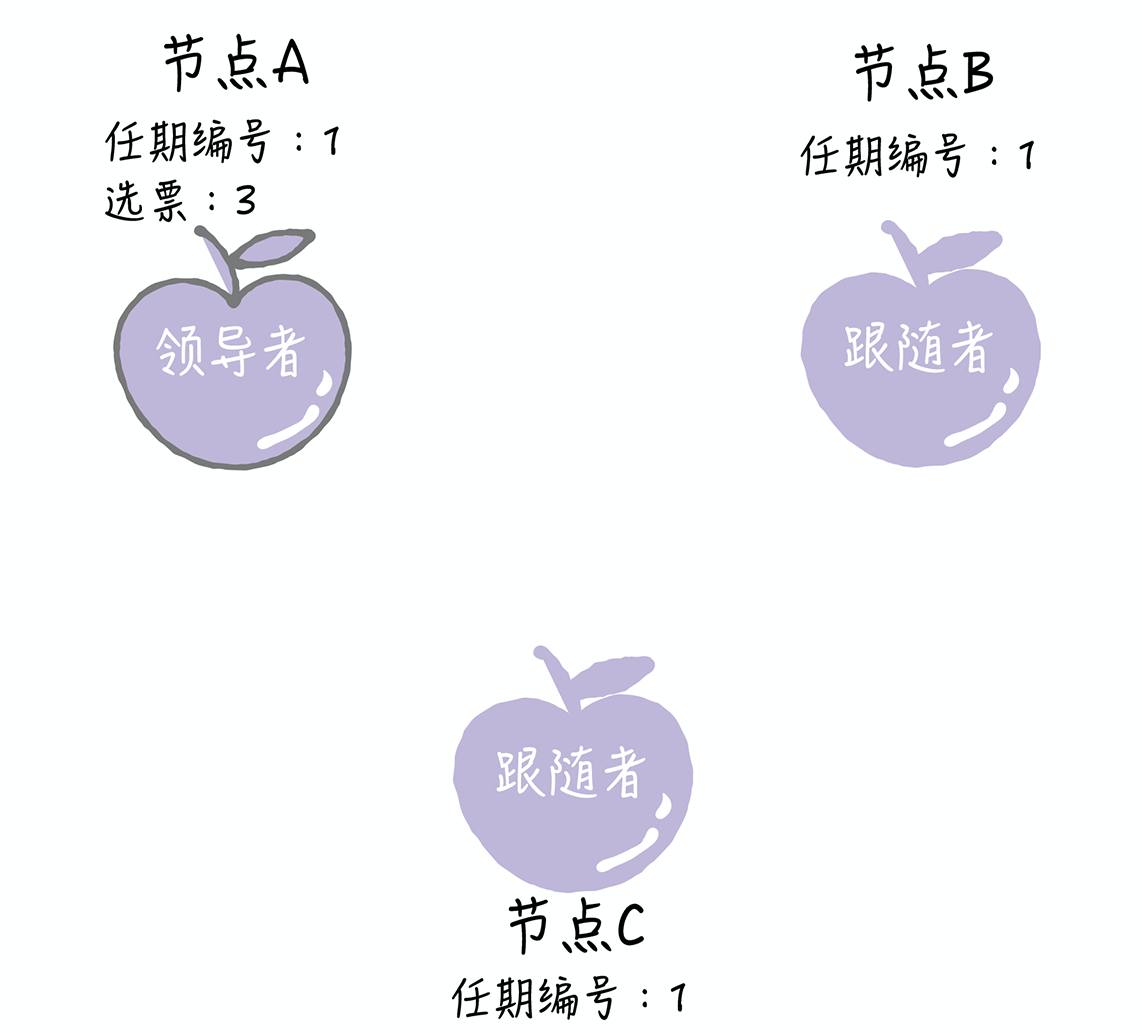
- 节点A当选领导者后,将周期性地发送心跳消息,通知其他服务器我是领导者,阻止跟随者发起新的选举,篡权

- Q:节点间如何通讯?
- 在Raft算法中,服务器节点间的沟通联络采用的是远程过程调用(RPC),在领导者选举中,需要用到两类RPC:
- 1.请求投票(RequestVote) RPC,由候选人在选举期间发起,通知各节点进行投票
- 2.日志复制(AppendEntries) RPC,由领导者发起,用来复制日志和提供心跳信息
- 注意:日志复制 RPC 只能由领导者发起,这是实现强领导者模型的关键之一
- 在Raft算法中,服务器节点间的沟通联络采用的是远程过程调用(RPC),在领导者选举中,需要用到两类RPC:
- Q:什么是任期?
- Raft算法中的领导者也是有任期的,每个任期由单调递增的数字(任期编号)标识,如节点A的任期编号是1。任期编号是随着选举的举行而变化的
- 1.跟随者在等待领导者心跳信息超时后,推举自己为候选人时,会增加自己的任期号,如节点A的当前任期编号为0,那么在推举自己为候选人时,会将自己的任期编号加1
- 2.如果一个服务器节点,发现自己的任期编号比其它节点小,那么它会更新自己的编号到较大的编号值。如节点B的任期编号是0,当收到来自节点A的请求投票RPC消息时,因为信息中包含了结点A的任期编号,且编号为1,那么节点B将把自己的任期编号更新为1
- Raft 算法中的任期不只是时间段,而且任期编号的大小,会影响领导者选举和请求的处理
- 1.在Raft算法中约定,如果一个候选人或领导者,发现自己的任期编号比其它节点小,那么它会立即恢复成跟随者状态。比如分区错误恢复后,任期编号为3的领导者节点B,收到来自新领导者的,包含任期编号为4的心跳信息,那么节点B将立即恢复成跟随者状态
- 2.还约定如果一个节点接收到一个包含较小的任期编号值的请求,那么它会直接拒绝这个请求。如节点C的任期编号为4,收到包含任期编号为3的请求投票RPC消息,那么它将拒绝这个消息
- Raft算法中的领导者也是有任期的,每个任期由单调递增的数字(任期编号)标识,如节点A的任期编号是1。任期编号是随着选举的举行而变化的
- Q:选举有哪些规则?
- 1.领导者周期性地向所有跟随者发送心跳信息(即不包含日志项的日志复制RPC消息),通知大家我是领导者,阻止跟随者发起新的选举
- 2.如果在指定时间内,跟随者没有接收到来自领导者的消息,那么它就认为当前没有领导者,推举自己为候选人,发起领导者选举
- 3.在一次选举中,赢得大多数选票的候选人,将晋升为领导者
- 4.在一个任期内,领导者一直都会是领导者,直到它自身出现问题(如宕机),或者因为网络延迟,其它节点发起一轮新的选举
- 5.在一次选举中,每一个服务器节点最多会对一个任期编号投出一章选票,并且按照「先来先服务」的原则进行投票。如节点C的任期编号为3,先收到了1个包含任期编号为4的投票请求(来自节点A),然后又收到了1个包含任期编号为4的投票请求(来自节点B)。那么节点C将会把唯一一张选票投给节点A,当再收到节点B的投票请求RPC 消息时,对于编号为 4 的任期,已没有选票可投了
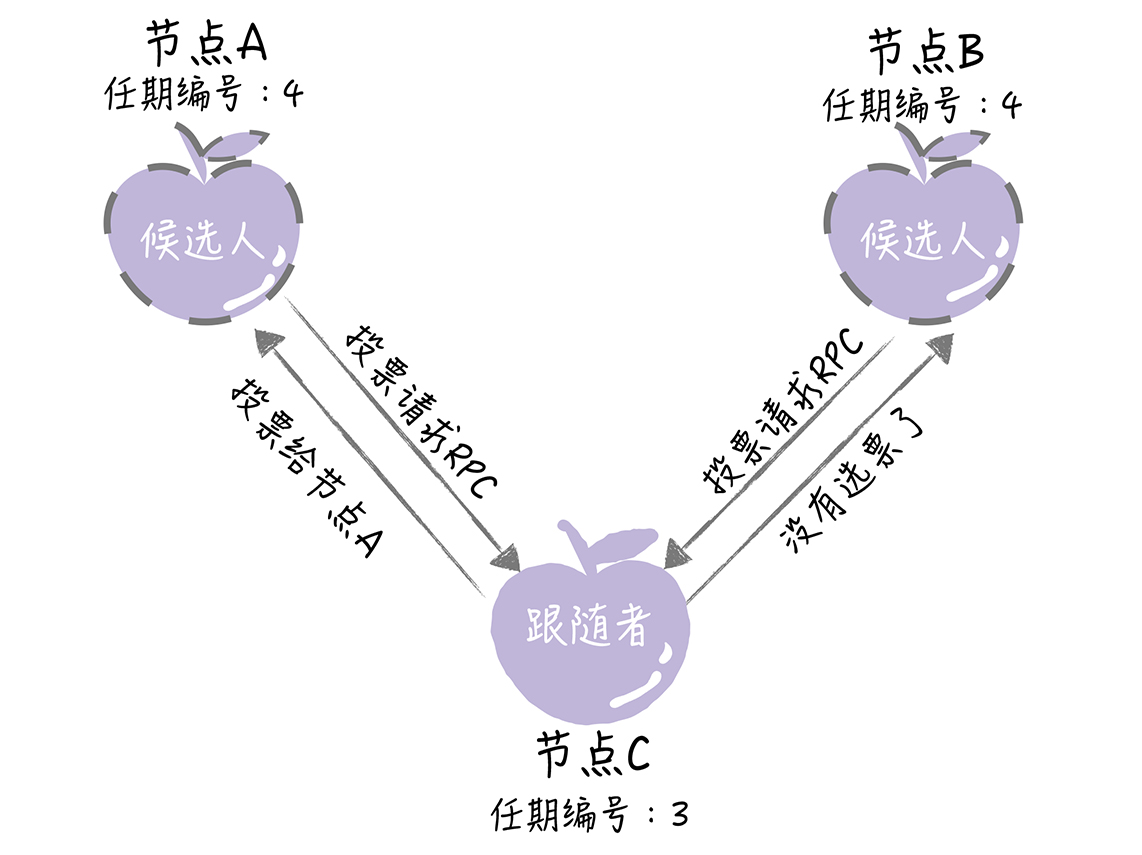
- 6.当任期编号相同时,日志完整性高的跟随者(即最后一条日志项对应的任期编号值更大,索引号更大),拒绝投票给日志完整性低的候选人。比如节点B、C的任期编号都是3,节点B的最后一条日志项对应的任期编号为3,而节点C为2,那么当节点C请求节点B投票给自己时,节点B将拒绝投票

- 注意:选举时跟随者发起的,推举自己为候选人;大多数选票是指集群成员半数以上的选票;大多数选票规则的目标,是为了保证在一个给定的任期内最多只有一个领导者
- 除了选举规则外,还需要避免一些会导致选举失败的情况,如同一任期内,多个候选人同时发起选举,导致选票被瓜分,选举失败。在Raft使用随机超时时间来避免这个问题
- Q:如何理解随机超时时间?
- Raft 算法巧妙地使用随机选举超时时间的方法,把超时时间都分散开来,在大多数情况下只有一个服务器节点先发起选举,而不是同时发起选举,这样就能减少因选票瓜分导致选举失败的情况
- Raft算法的随机超时时间的 2 种含义
- 1.跟随者等待领导者心跳信息超时的时间间隔,是随机的
- 2.当没有候选人赢得过半票数,选举无效了,这时需要等待一个随机时间间隔,即等待选举超时的时间间隔,是随机的
08 | Raft算法(二):如何复制日志?
- Q:Raft算法中的日志是什么?
- 在Raft算法中,副本数据以日志的形式存在,日志是由日志项组成,日志项是一种数据格式,主要包含用户指定的数据,即指令(Command),和一些附加信息,如索引值(Log index)、任期编号(Term)
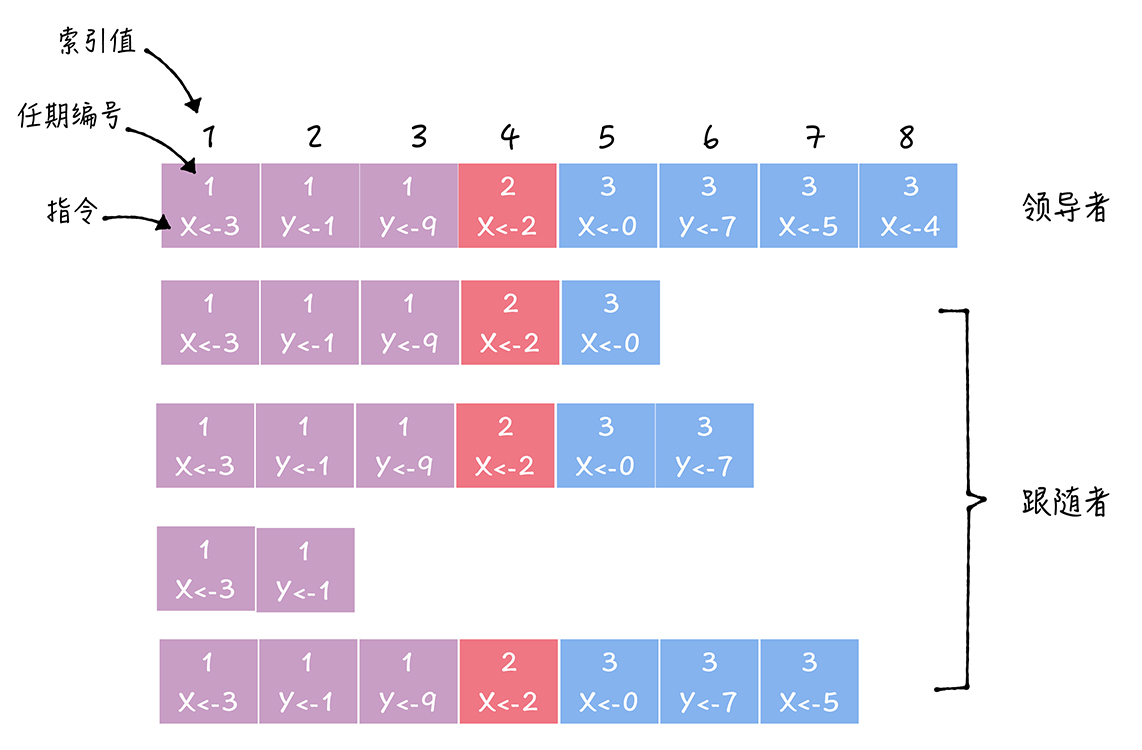
- 指令:一条由客户端请求指定的、状态机需要执行的指令。可理解成客户端指定的数据
- 索引值:日志项对应的整数索引值,用来标识日志项,是一个连续的、单调递增的整数号码
- 任期编号:创建这条日志项的领导者的任期编号
- 注意:一届领导者任期,往往有多条日志项。而且日志项的索引值是连续的
- Q:如何复制日志?
- 可把Raft 的日志复制理解成一个优化后的二阶段提交(将二阶段优化成了一阶段),减少了一半的往返消息,也就是降低了一半的消息延迟
- 1.领导者进入第一阶段,通过日志复制(AppendEntries) RPC消息,将日志项复制到其它节点上
- 2.如果领导者接收到大多数的「复制成功」响应后,它将日志项提交到它的状态机,并返回成功给客户端。如果领导者没有接收到大多数的“复制成功”响应,那么就返回错误给客户端
- Q:领导者将日志项提交到它的状态机,为什么没通知跟随者提交日志项?
- 这是 Raft 中的一个优化,领导者不直接发送消息通知其它节点提交指定日志项。因为领导者的日志复制RPC消息或心跳消息,包含了当前最大的,将会被提交的日志项索引值。所以通过日志复制RPC消息或心跳消息,跟随者就可以知道领导者的日志提交位置信息
- 因此,当其它节点接受领导者的心跳信息,或者新的日志复制RPC消息后,就会将这条日志项提交到它的状态机。这个优化,降低了处理客户端请求的延迟,将二阶段提交优化为一阶段提交,降低了一半的消息延迟
- Q:日志复制过程?
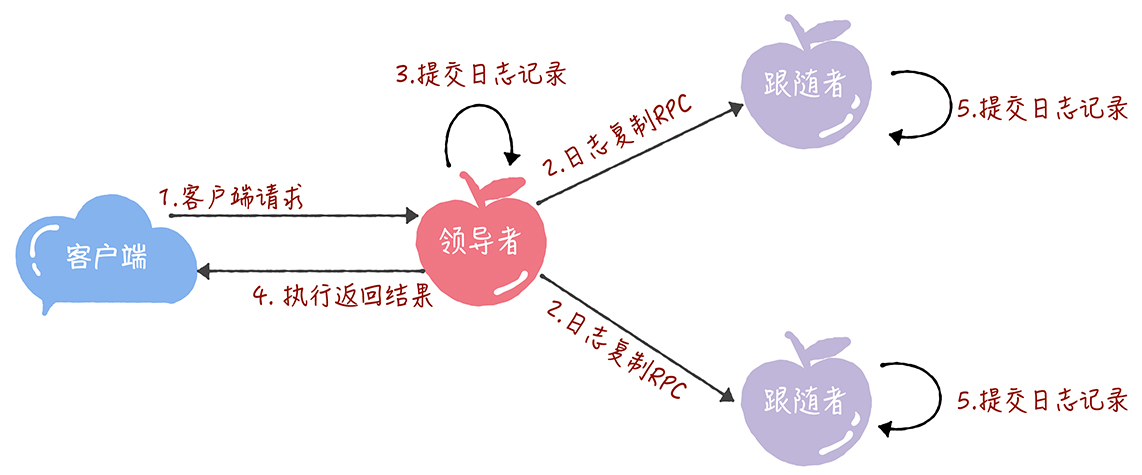
- 1.接收到客户端请求后,领导者基于客户端请求中的指令,创建一个新日志项,并附加到本地日志中
- 2.领导者通过日志复制RPC,将新的日志项复制到其它的服务器
- 3.当领导者将日志项,成功复制到大多数服务器上的时候,领导者会将这条日志项提交到它的状态机中
- 4.领导者将执行的结果返回给客户端
- 5.当跟随者接收到心跳信息,或者新的日志复制RPC消息后,如果跟随者发现领导者已经提交了某条日志项,而它还没提交,那么跟随者就将这条日志项提交到本地的状态机中
- Q:如何实现日志的一致?
- 在Raft算法中,,领导者通过强制跟随者直接复制自己的日志项,处理不一致日志。即Raft是通过以领导者的日志为准,来实现各节点日志的一致的
- 1.领导者通过日志复制RPC的一致性检查,找到跟随者节点上,与自己想通日志项的最大索引值。即在这个索引值之前的日志,领导者和跟随者是一致的,之后的日志是不一致的了
- 2.领导者强制跟随者更新覆盖不一致的日志项,实现日志的一致
- Q:Raft实现日志的一致的详细过程
- 引入2个新变量
- PrevLogEntry:表示当前要复制的日志项,前面一条日志项的索引值。如在图中,如果领导者将索引值为8的日志项发送给跟随者,那么此时 PrevLogEntry 值为7
- PrevLogTerm:表示当前要复制的日志项,前面一条日志项的任期编号,如在图中,如果领导者将索引值为8的日志项发送给跟随者,那么此时PrevLogTerm值为4
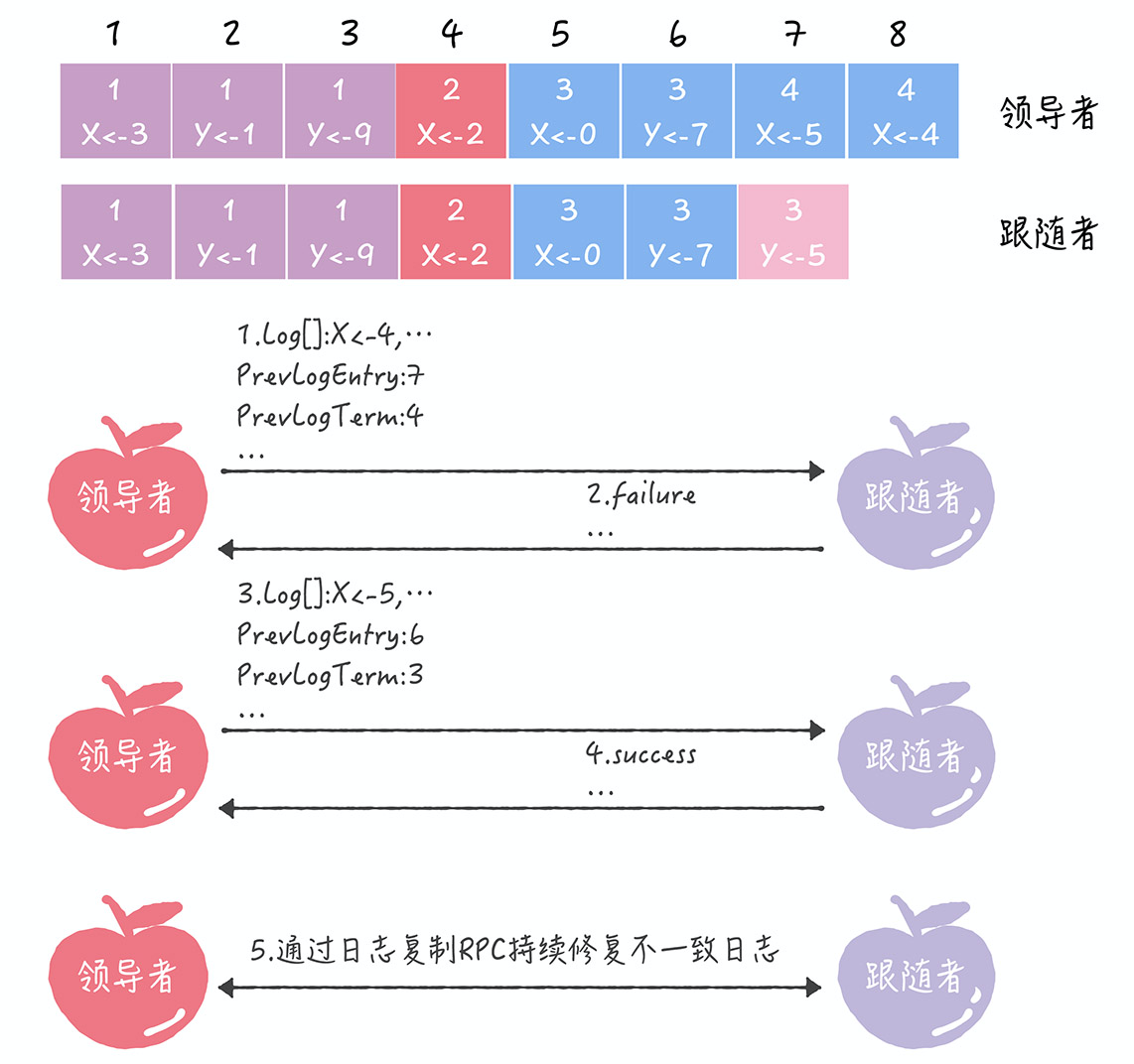
- 1.领导者通过日志复制RPC消息,发送当前最新日志项到跟随者,这个消息的PrevLogEnetry值为7,PrevLogTerm值为4
- 2.如果跟随者在它的日志中,找不到与PrevLogEntry值为7、PrevLogTerm值为4的日志项,即它的日志和领导者的不一致了,那么跟随者者就会拒绝接收新的日志项, 并返回失败信息给领导者
- 3.这时,领导者会递减要复制的日志项的索引值,并发送新的日志项到跟随者,这个消息的 PrevLogEntry 值为 6,PrevLogTerm 值为 3
- 4.如果跟随者在它的日志中,找到了 PrevLogEntry 值为 6、PrevLogTerm 值为 3 的日志项,那么日志复制 RPC 返回成功,这样一来,领导者就知道在 PrevLogEntry 值为 6、PrevLogTerm 值为 3 的位置,跟随者的日志项与自己相同
- 5.领导者通过日志复制RPC,复制并更新覆盖索引值后的日志项(即不一致的日志项),最终实现了集群各节点日志的一致
- 从上面步骤中可以看到,领导者通过日志复制 RPC 一致性检查,找到跟随者节点上与自己相同日志项的最大索引值,然后复制并更新覆盖该索引值之后的日志项,实现了各节点日志的一致。注意,跟随者中的不一致日志项会被领导者的日志覆盖,而且领导者从来不会覆盖或者删除自己的日志
- 引入2个新变量
10 | 一致哈希算法:如何分群,突破集群的“领导者”限制?
- Q:使用哈希算法实现哈希寻址时,有什么问题?
- 通过哈希算法,每个 key 都可以寻址到对应的服务器,比如,查询 key 是 key-01,计算公式为 hash(key-01) % 3 ,经过计算寻址到了编号为 1 的服务器节点 A
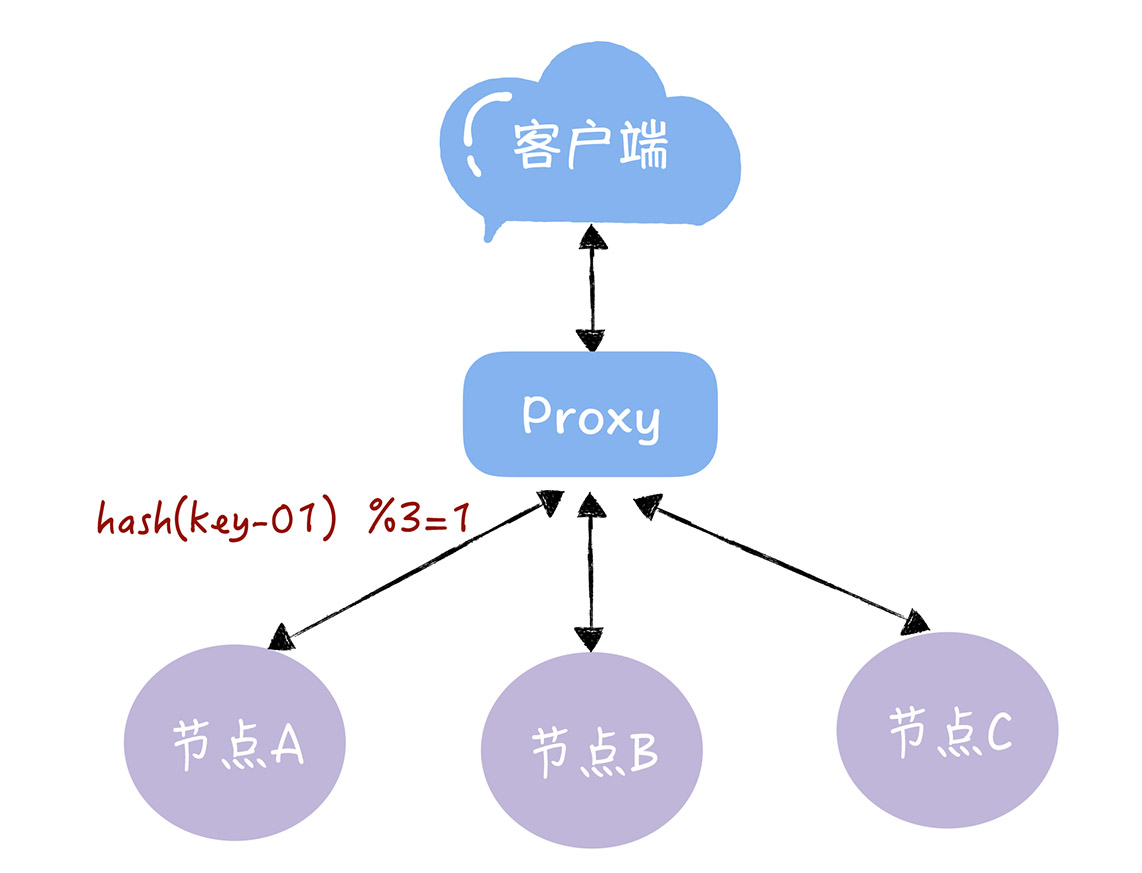
- 但如果服务器数量发生变化,基于新的服务器数量来执行哈希算法的时候,就会出现路由寻址失败的情况,Proxy 无法找到之前寻址到的那个服务器节点
- 假如 3 个节点不能满足业务需要了,这时我们增加了一个节点,节点的数量从 3 变化为 4,那么之前的 hash(key-01) % 3 = 1,就变成了 hash(key-01) % 4 = X,因为 取模运算发生了变化,所以这个 X 大概率不是 1(可能 X 为 2),这时你再查询,就会找 不到数据了,因为 key-01 对应的数据,存储在节点 A 上,而不是节点 B
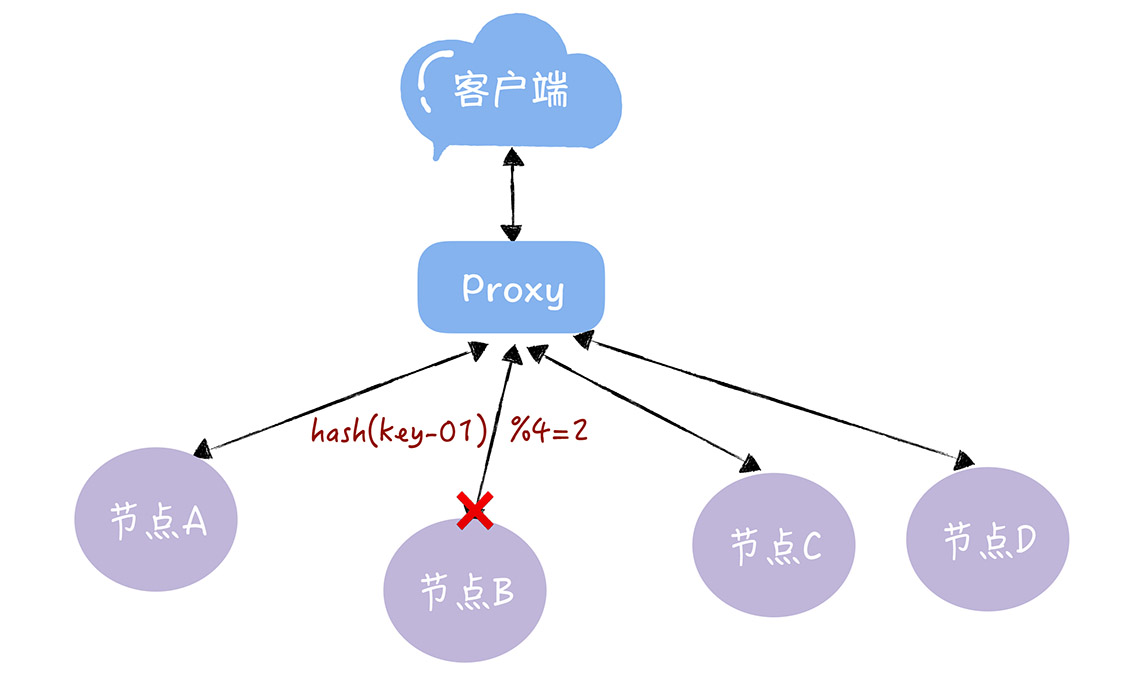
- 同样的道理,如果我们需要下线 1 个服务器节点(也就是缩容),也会存在类似的可能查询不到数据的问题
- 而解决这个问题的办法,在于我们要迁移数据,基于新的计算公式 hash(key-01) % 4 ,来重新对数据和节点做映射。需要你注意的是,数据的迁移成本是非常高的
- 对于 1000 万 key 的 3 节点 KV 存储,如果我们增加 1 个 节点,变为 4 节点集群,则需要迁移 75% 的数据
- Q:如何使用一致哈希实现哈希寻址
- 一致哈希算法是对 2^32 进行取模运算,将整个 哈希值空间组织成一个虚拟的圆环,即哈希环
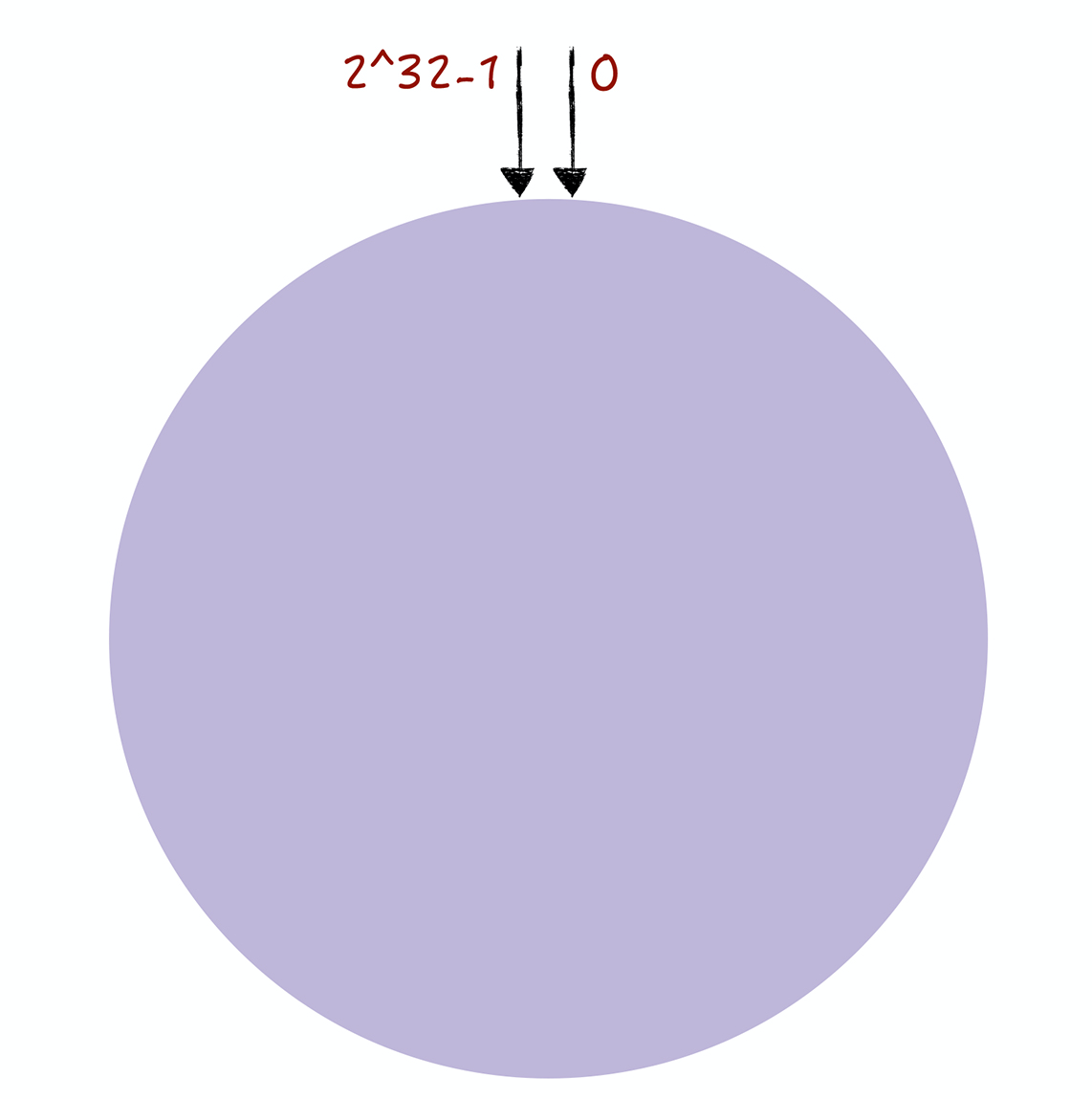
- 哈希环的空间是按顺时针方向组织的,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到 2^32-1,即 0 点左 侧的第一个点代表 2^32-1
- 在一致哈希中,通过执行哈希算法将节点映射到哈希环上,比如选择节点的主机名作为参数执行 c-hash(),那么每个节点就能确定其在哈希环上的位置了
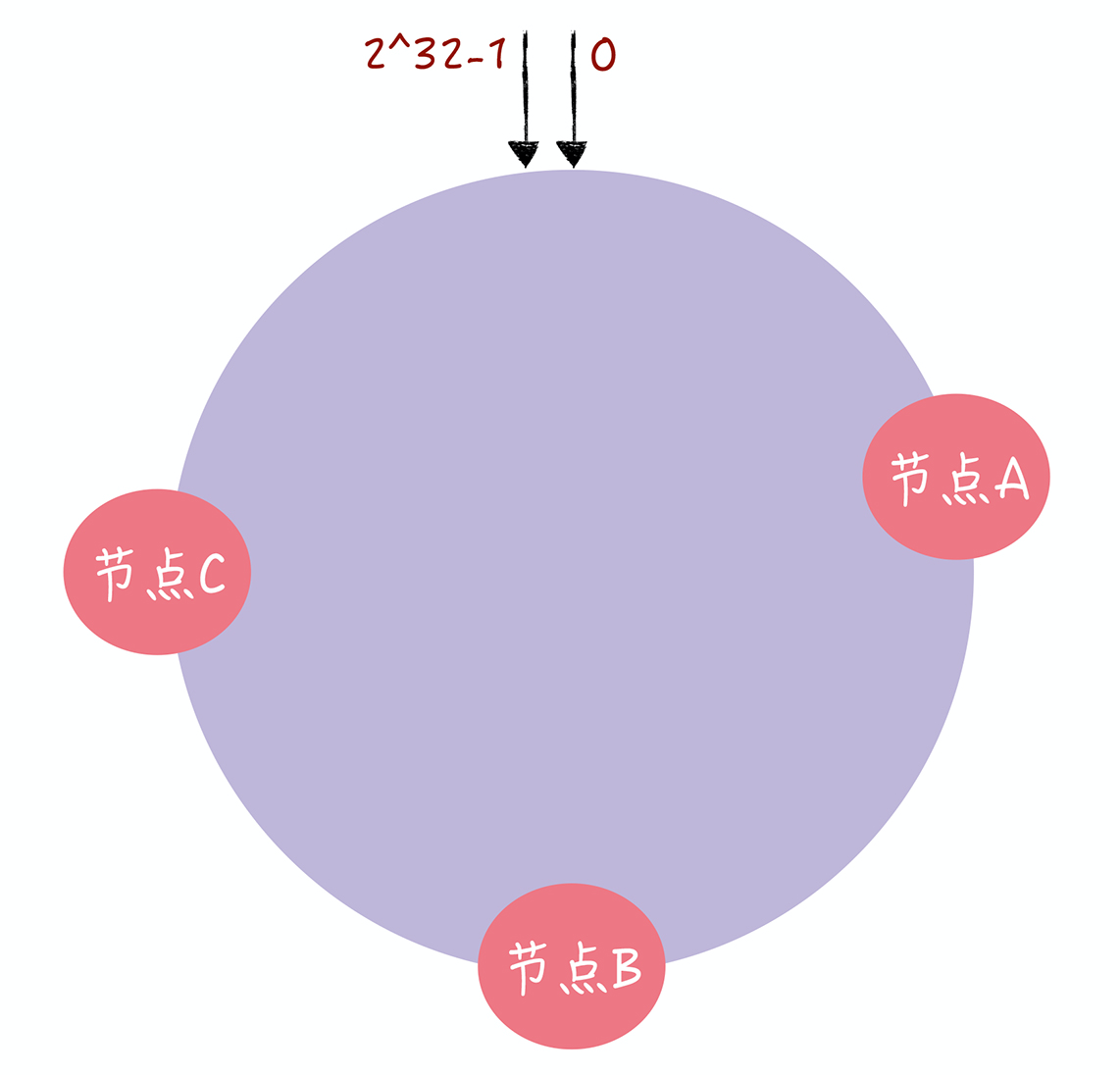
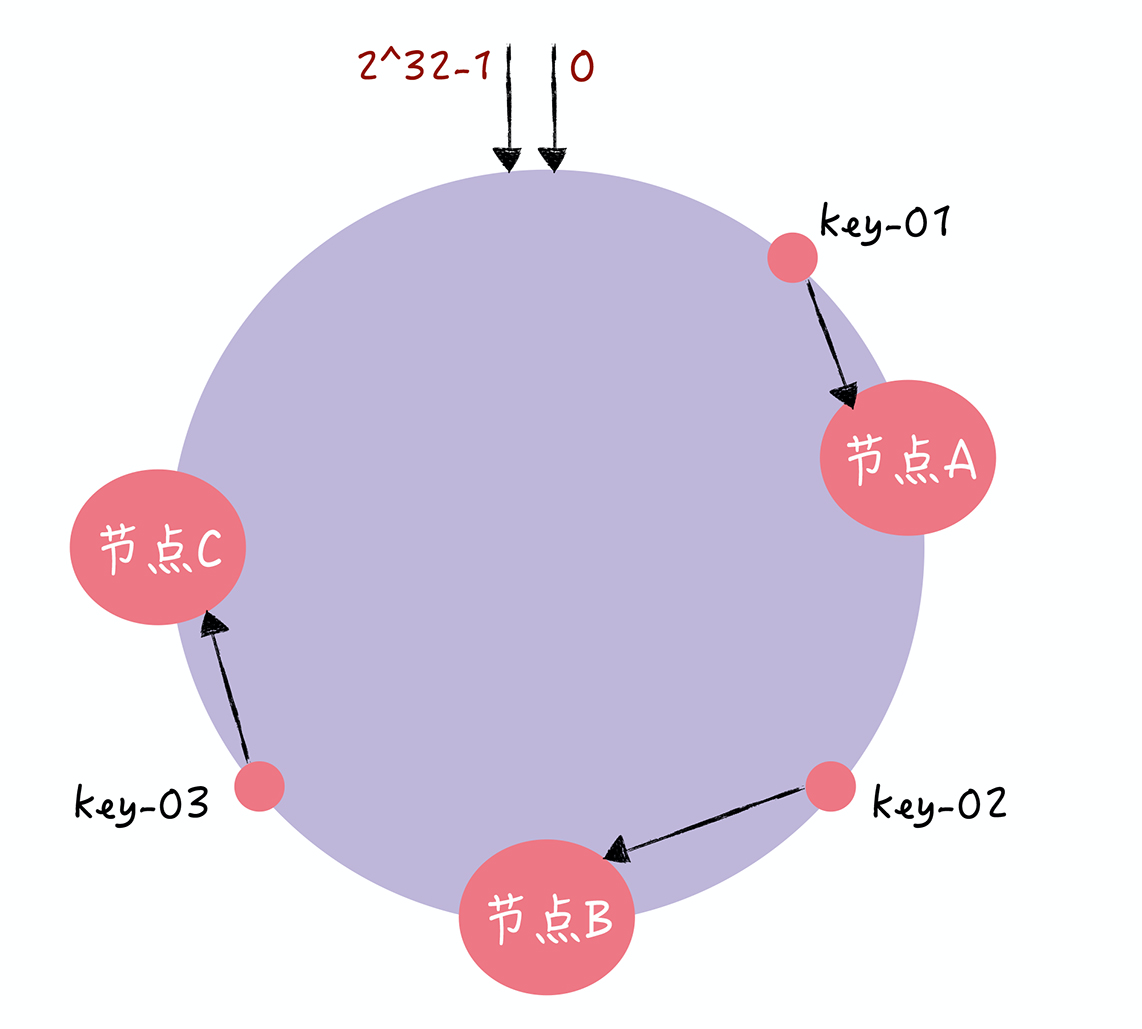
- Q:对指定 key 的值进行读写的时候,通过哪 2 步进行寻址?
- 1.将key作为参数执行 c-hash() 计算哈希值,并确定此 key 在环上的位置
- 2.从这个位置沿着哈希环顺时针“行走”,遇到的第一节点就是 key 对应的节点
- Q:有一个节点故障了(如节点C),一致哈希是怎么处理的
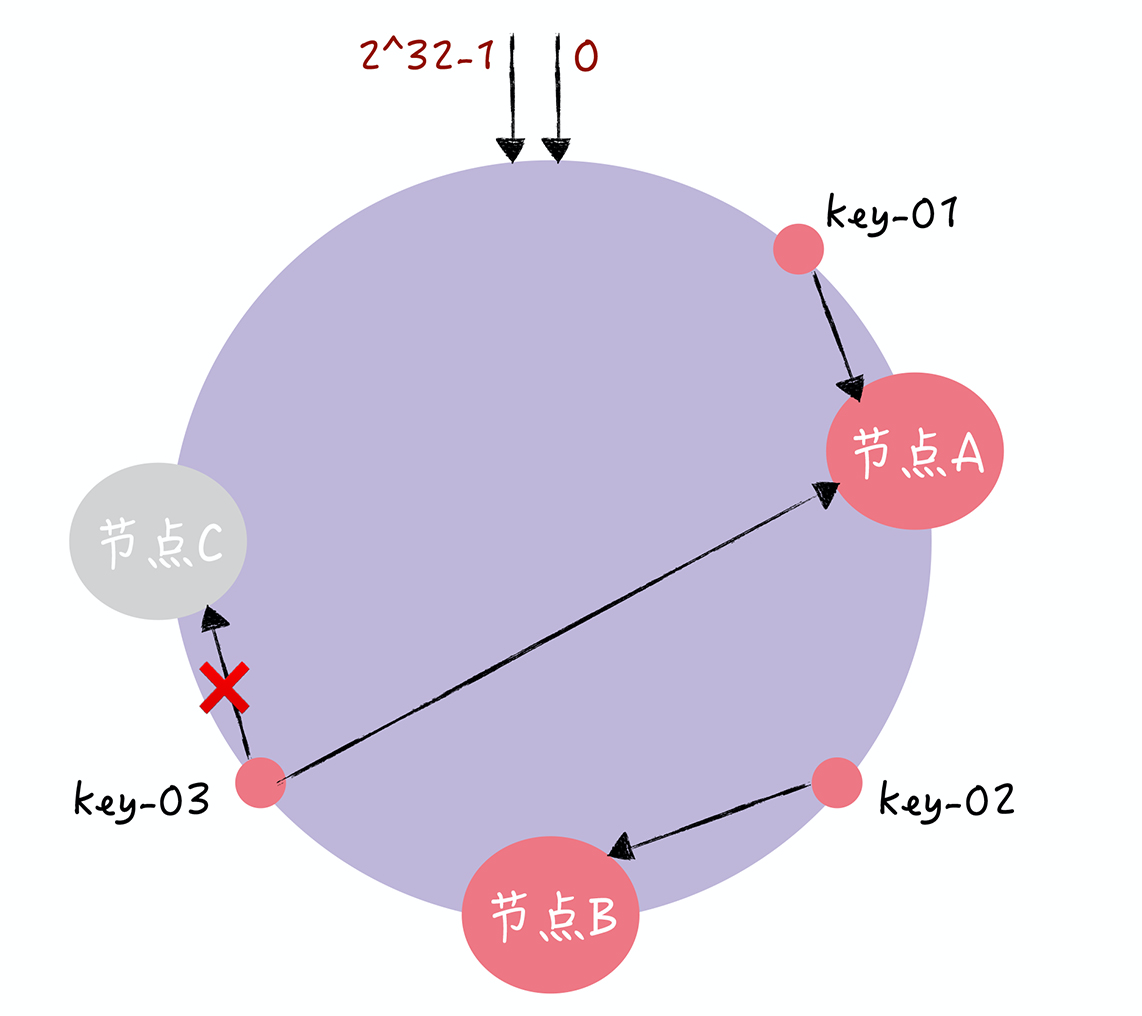
- key-01 和 key-02 不会受到影响,只有 key-03 的寻址被重定位到 A。一般来说,在一致哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是,会寻址到此节点和前一节点之间的数据
- 如当节点 C 宕机了,受影响的数据是会寻址到节点 B 和节点 C 之间的数据(例如 key-03),寻址到其他哈希环空间的数据(例如 key-01),不会受到影响
- Q:需要扩容一个节点,一致哈希是怎么处理的
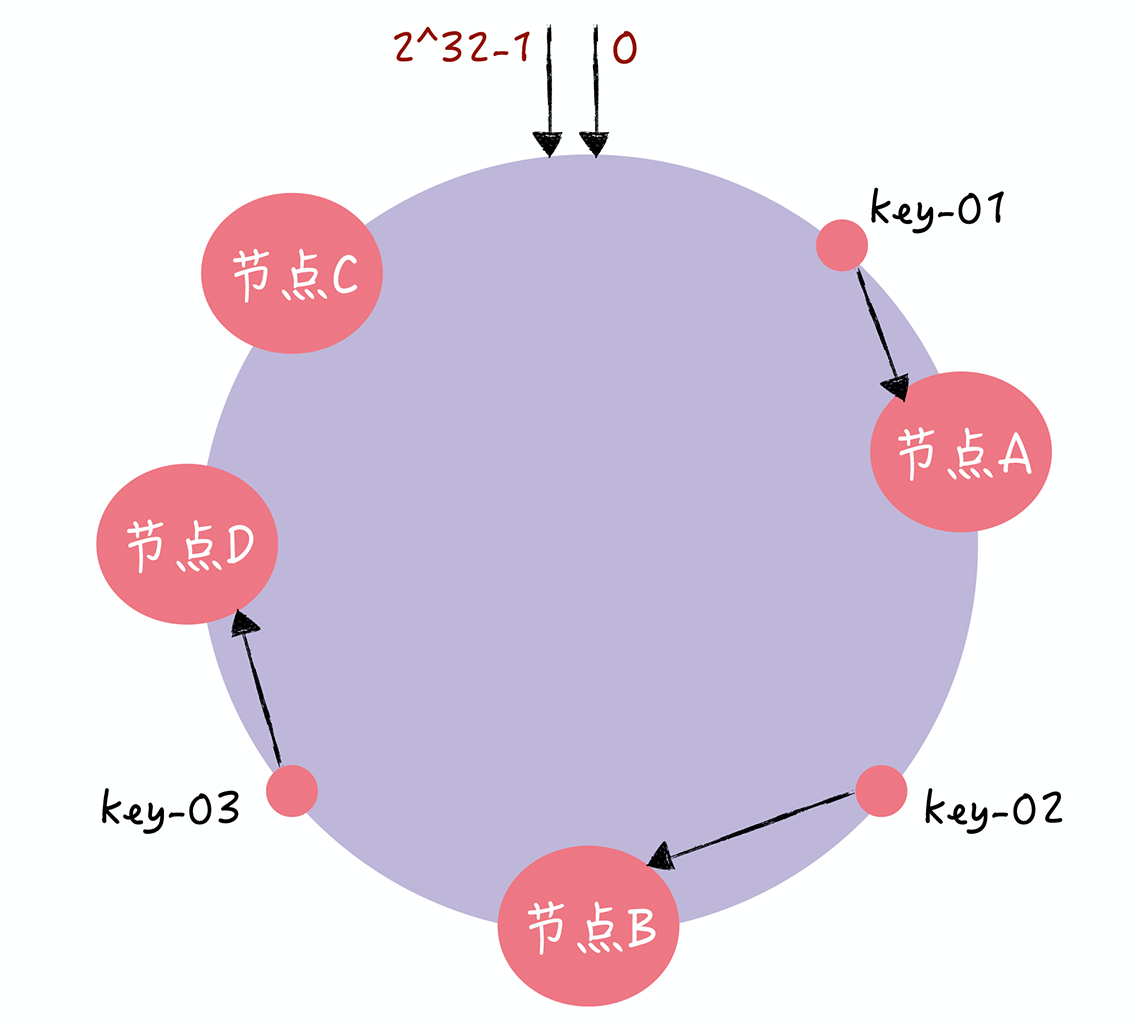
- key-01、key-02 不受影响,只有 key-03 的寻址被重定位到新节点 D。一般 而言,在一致哈希算法中,如果增加一个节点,受影响的数据仅仅是,会寻址到新节点和前 一节点之间的数据,其它数据也不会受到影响
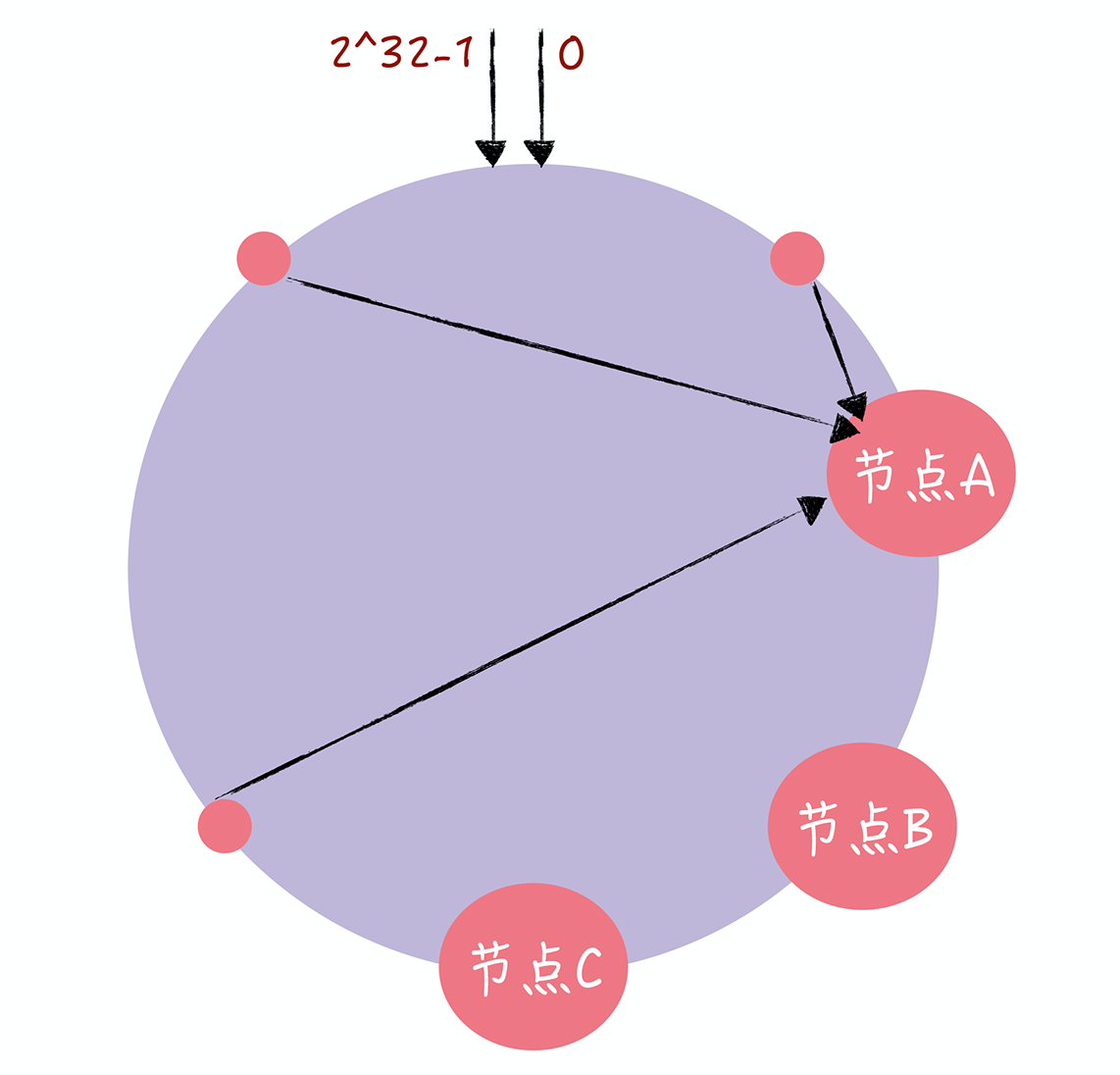
- Q:在一致哈希中,客户端访问请求集中在少数的节点上,为什么会出现有些机器高负载,有些机器低负载的情况
- 在一致哈希中,如果节点太少,容易因为节点分布不均匀造成数据访问的冷热不均,即大多数访问请求都会集中少量几个节点上
- Q:如何通过虚拟节点解决冷热不均的问题?
- 对每一个服务器节点计算多个哈希值,在每个计算结果位置上,都放置一个虚拟 节点,并将虚拟节点映射到实际节点。比如,可以在主机名的后面增加编号,分别计算 “Node-A-01”“Node-A-02”“Node-B-01”“Node-B-02”“Node-C01”“Node-C-02”的哈希值,于是形成 6 个虚拟节点
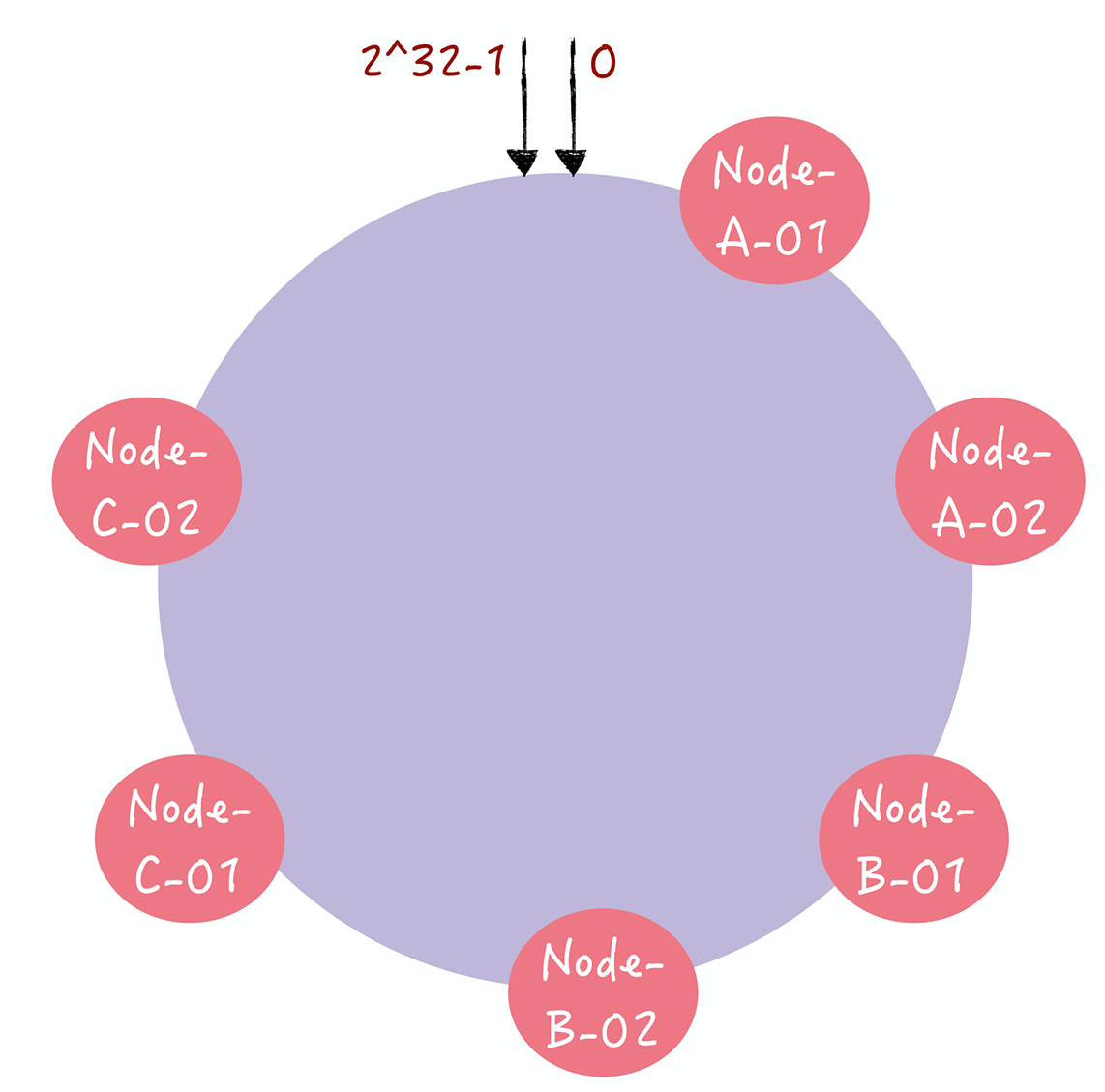
- 增加了节点后,节点在哈希环上的分布就相对均匀了。这时,如果有访问请求寻址到“Node-A-01”这个虚拟节点,将被重定位到节点 A。这样我们就解决了冷热不均的问题
11 | Gossip协议:流言蜚语,原来也可以实现一致性
- Q:Gossip的三板斧是什么?
- 直接邮寄(Direct Mail)
- 反熵(Anti-entropy)
- 谣言传播(Rumor mongering)
- Q:直接邮寄是什么?
- 直接发送更新数据,当数据发送失败时,将数据缓存下来,然后重传。直接邮寄虽然实现起来比较容易,数据同步也很及时,但可能会因为缓存队列满了而丢数据。即只采用直接邮寄是无法实现最终一致性的
- Q:反熵是什么?
- 集群中的节点,每隔段时间就随机选择某个其它节点,然后通过互相交换自己的所有数据来消除两者之间的差异,实现数据的最终一致性

- 如上图,节点A通过反熵的方式,修复了节点 D 中缺失的数据
- 注意,因为反熵熵需要节点两两交换和比对自己所有的数据,执行反熵时通讯成本会很高,不建议频繁执行,可通过引入校验和(Checksum)等机制,降低需要对比的数据量和通讯消息
- 执行反熵时相关的节点都是已知的,而且节点数量不能太多,如果是一个动态变化或节点数比较多的分布式环境,这时反熵就不适用了,该用谣言传播
- Q:反熵修复节点缺失数据的3种方式
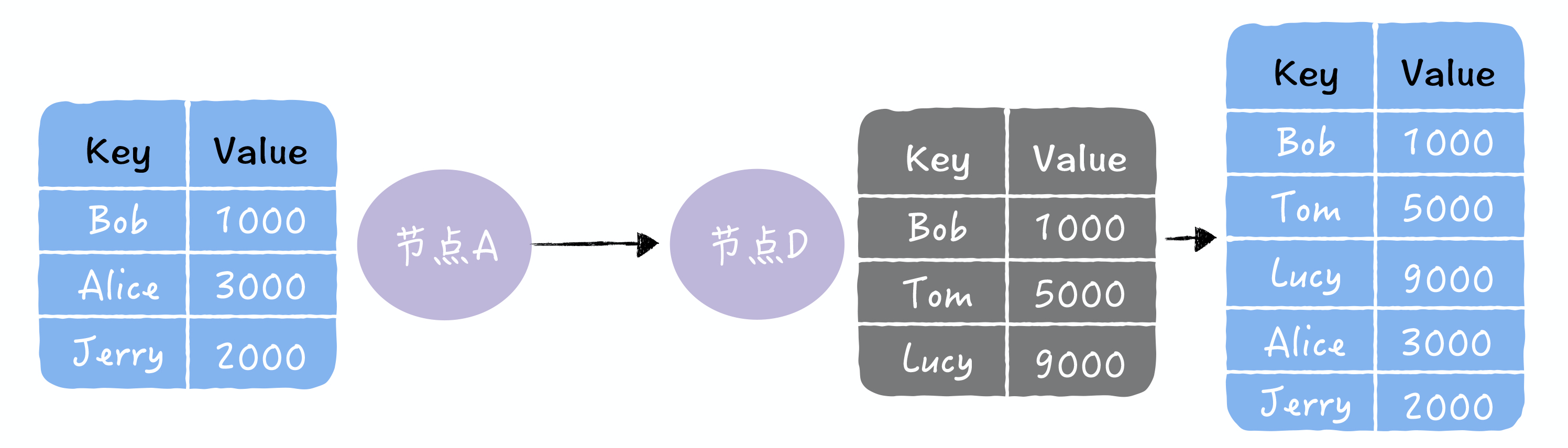
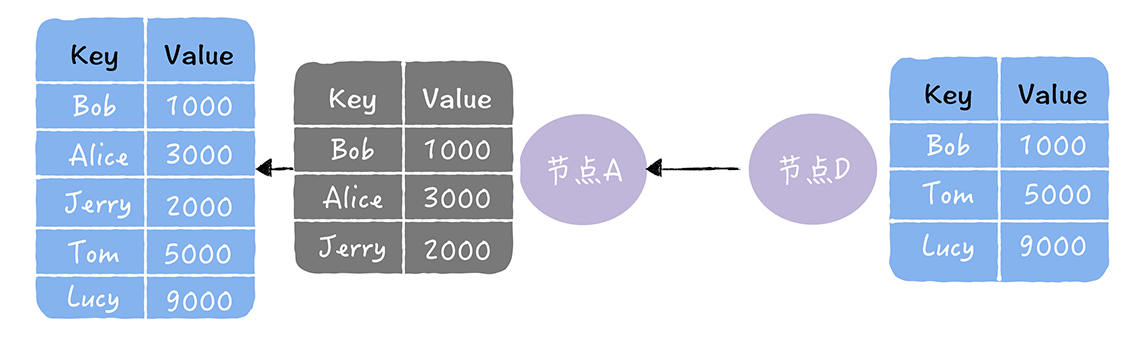
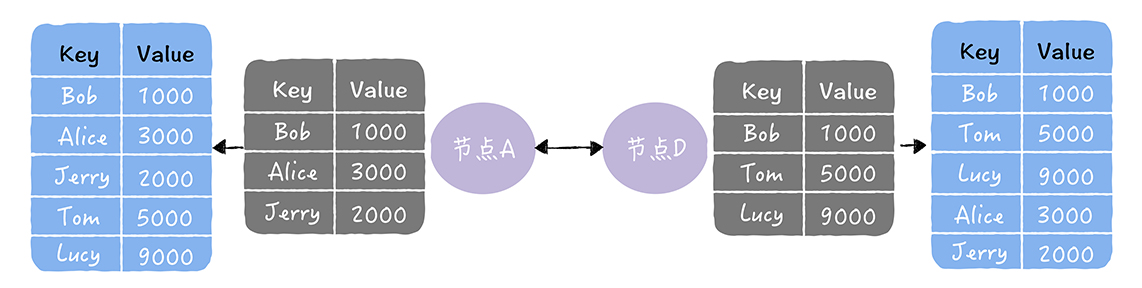
- 以下图中,2 个数据副本的不一致为例
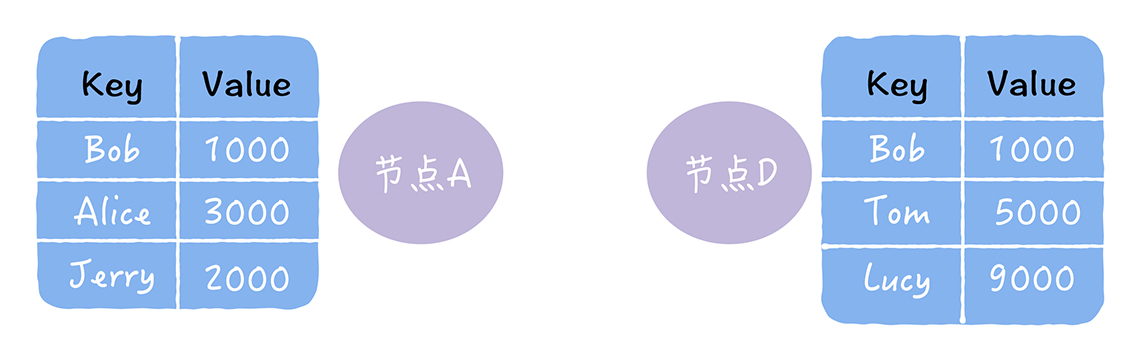
- 推:将自己的所有副本数据,推给对方,修复对方副本中的熵
- 拉:拉取对方的所有副本数据,修复自己副本中的熵
- 推拉:同时修复自己副本和对方副本中的熵
- Q:谣言传播是什么?
- 当一个节点有了新数据后,这个节点编程活跃状态,并周期性地联系其他节点向其发送新数据,直到所有的节点都存储了该新数据
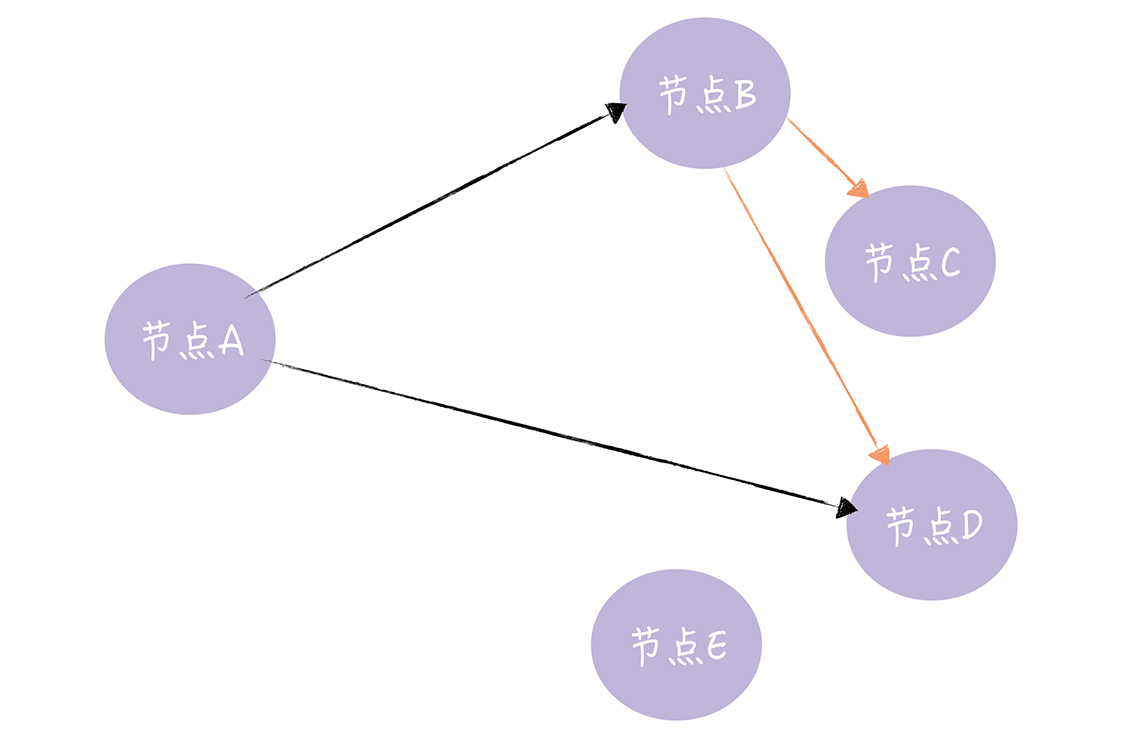
- 如图,节点 A 向节点 B、D 发送新数据,节点 B 收到新数据后,变成活跃节点,然后节点 B 向节点 C、D 发送新数据。谣言传播非常具有传染性,它适合动态变化的分布式系统
12 | Quorum NWR算法:想要灵活地自定义一致性,没问题!
- Q:最终一致性和强一致性有什么区别
- 强一致性能保证写操作完成后,任何后续访问都能读到更新后的值
- 最终一致性只能保证如果对某个对象没有新的写操作了,最终所有后续访问都能读到相同的最近更新的值,即写操作完成后,后续访问可能会读到旧数据
- Q:Quorum NWR的三要素
- N:副本数,又叫复制因子(Replication Factor)
- W:写一致性级别(Write Consistency Level),表示成功完成W个副本更新,才完成写操作
- R:读一致性级别(Read Consistency Level),表示读取一个数据对象时需要读R个副本,即,读取指定数据时,要读 R 副本,然后返回 R 个副本中最新的那份数据
- 注意:无论客户端如何执行读操作,哪怕它访问的是写操作未强制更新副本数据的节点(比如节点 B),但因为 W(2) + R(2) > N(3),也就是说,访问节点 B,执行读操作时,因为要读 2 份数据副本,所以除了节点 B 上的 DATA-2,还会读取节点 A 或节点 C 上的 DATA-2,就像上图的样子(比如节点 C 上的 DATA-2),而节点 A 和节点 C 的 DATA-2 数据副本是强制更新成功的。这个时候,返回给客户端肯定是最新的那份数据
- Q:N、W、R 值的不同组合,会产生哪两种不同的一致性效果?
- 当 W + R > N 时,对于客户端来说,整个系统能保证强一致性,一定能返回更新后的那份数据
- 当 W + R < N 时,对于客户端来说,整个系统只能保证最终一致性,可能会返回旧数据
- Q:any、one、quorum、all 这4种写一致性级别,具体的含义
- any:任何一个节点写入成功后,或者接收节点已将数据写入Hinted-handoff缓存(即写其他节点失败后,本地节点上缓存写失败数据的队列) 后,就会返回成功给客户端
- one:任何一个节点写入成功后,立即返回成功给客户端,,不包括成功写入到 Hinted-handoff 缓存
- quorum:当大多数节点写入成功后,就会返回成功给客户端。此选项仅在副本数大于 2 时才有意义,否则等效于 all
- all:仅在所有节点都写入成功后,返回成功