02丨数据结构:快速的Redis有哪些慢操作?
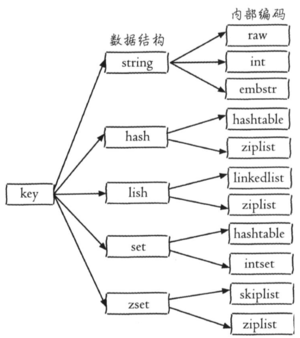
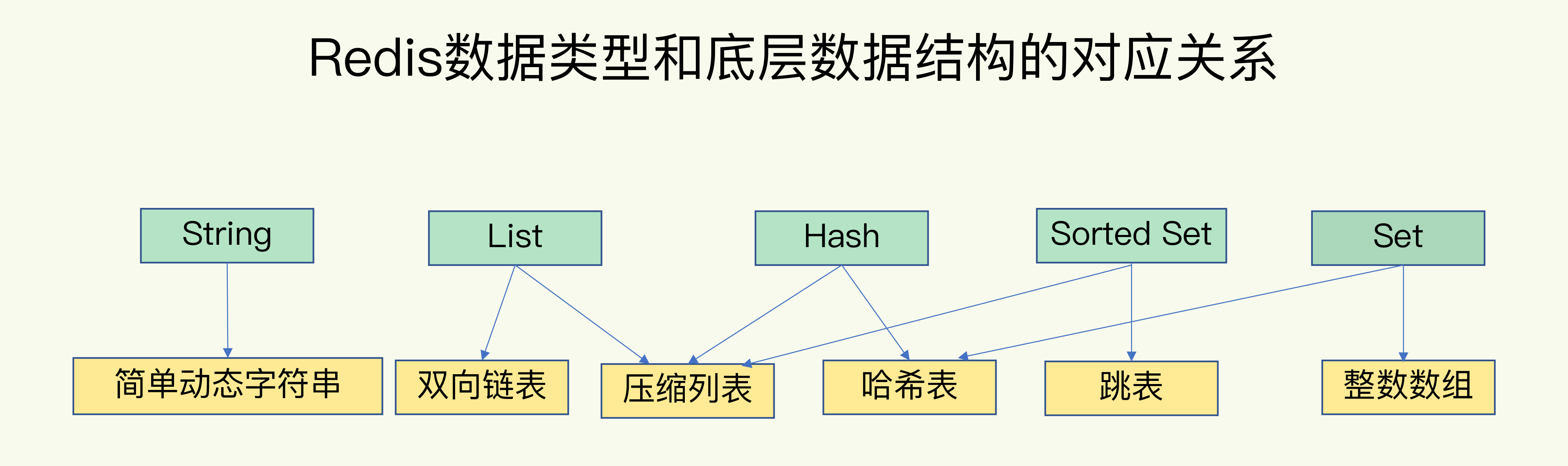
- Q:Redis的数据类型分别对应底层哪些数据结构?
- String:简单动态字符串
- List:压缩列表、双向链表
- Hash:压缩列表、哈希表
- Set:整数数组、哈希表
- Sorted Set:压缩列表、跳表
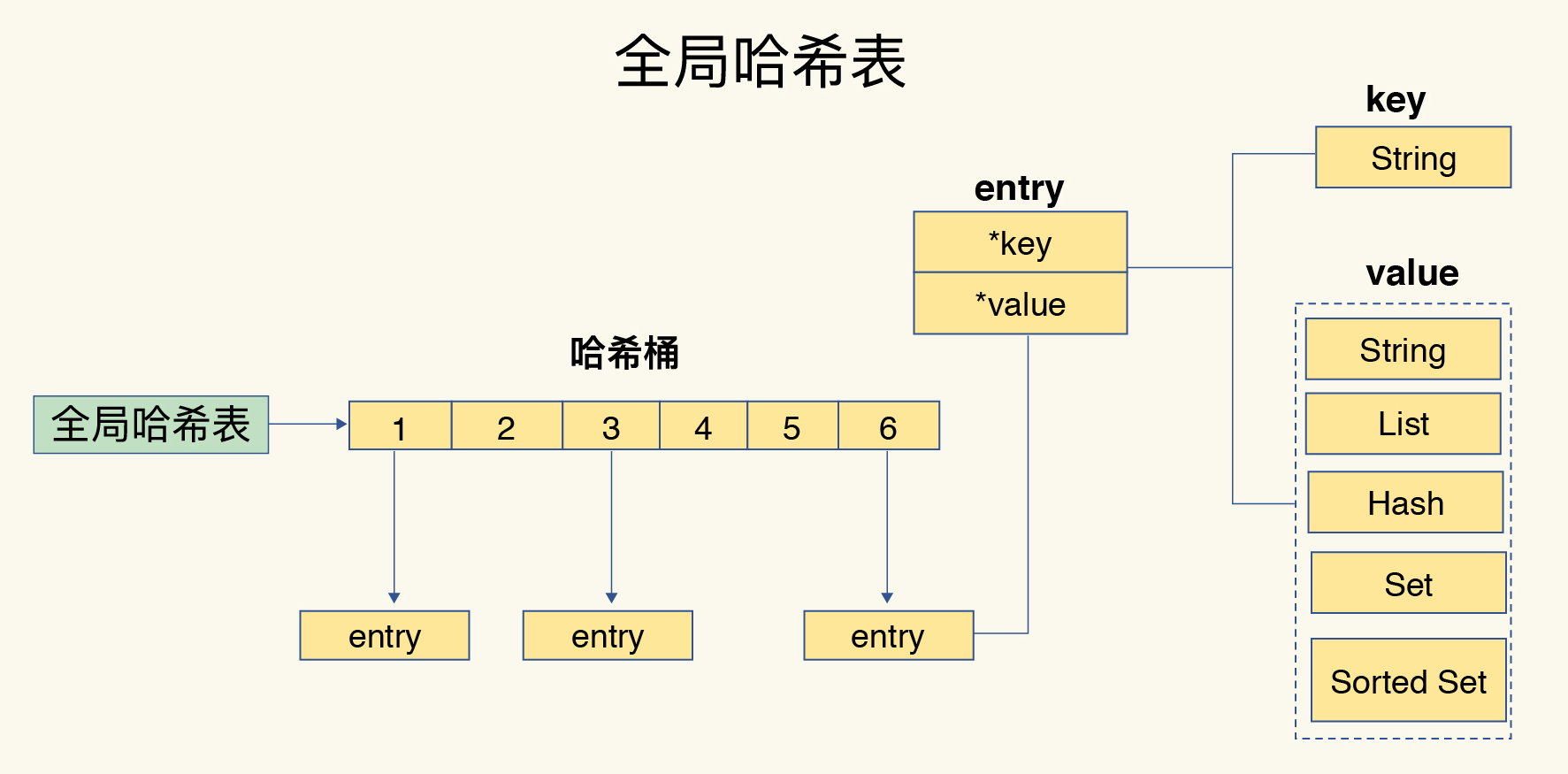
- Q:Redis的键和值使用什么结构组织?
- 使用一个全局哈希表,其实是一个数组,数组的每个元素称为一个哈希桶,每个哈希桶中保存了键值对数据
- 哈希桶中的 entry 元素中保存了 *key 和 *value 指针,分别指向了实际的键和值
- Q:Redis如何解决哈希冲突?
- 哈希冲突是,由于哈希桶的个数通常少于 key 的数量,计算两个 key 的哈希值正好落在同一个哈希桶中
- 解决:使用链式哈希,即同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接,该链表也叫哈希冲突链

- Q:rehash是什么?
- 增加现有的哈希桶数量,让逐渐增多的 entry 元素能在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突
- Q:Redis 使 rehash 更高效的方法是什么?
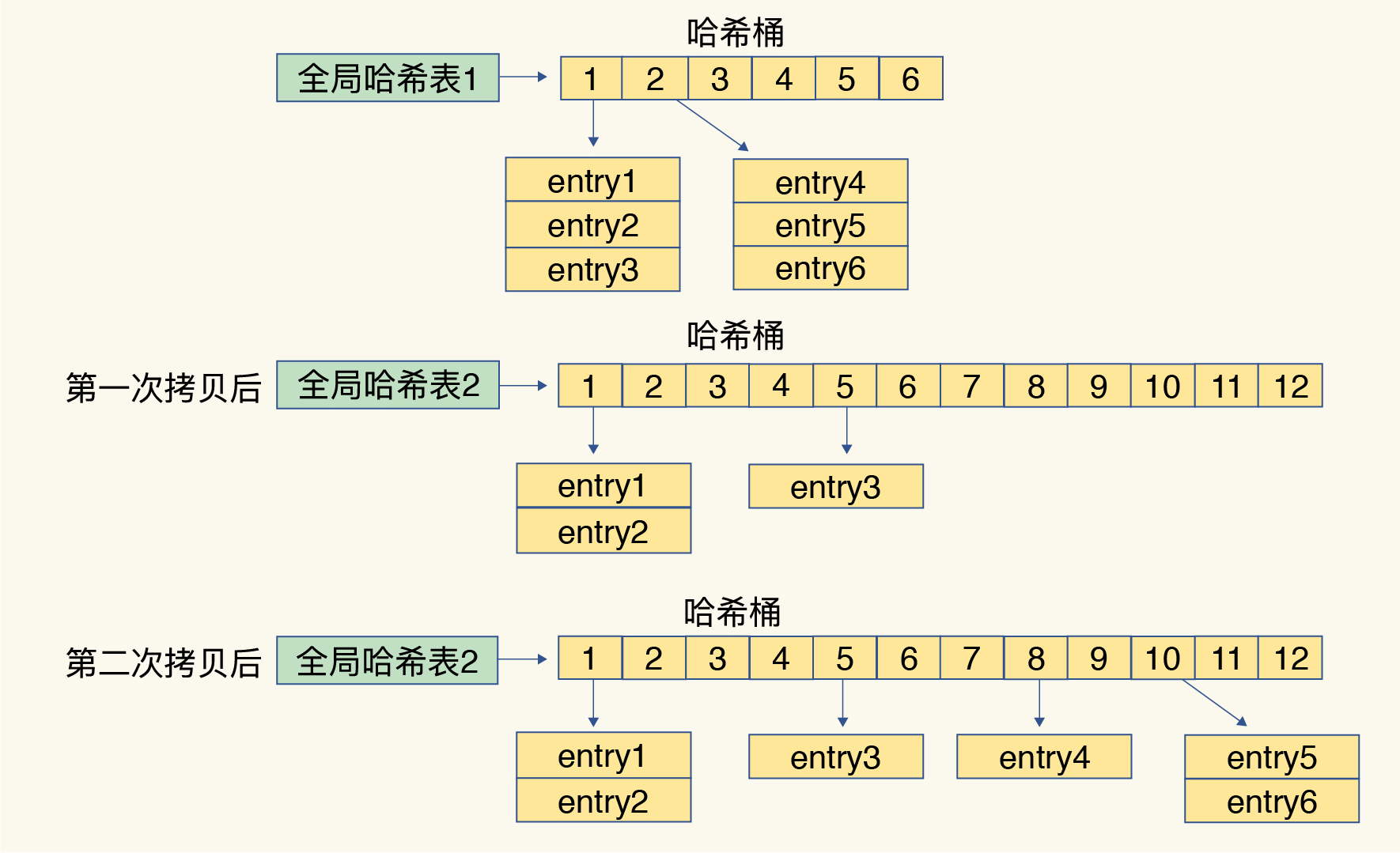
- 默认使用了两个全局哈希表:哈希表 1 和哈希表 2
- 一开始默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash
- rehash 完毕后从哈希表 1 切换到哈希表 2,用增大的哈希表 2 保存更多数据,而原来的哈希表 1 留作下一次 rehash 扩容备用
- Q:rehash 的步骤是什么?
- 1.给哈希表2分配更大的空间,例如是当前哈希表1大小的两倍
- 2.把哈希表1中的数据重新映射并拷贝到哈希表2中
- 3.释放哈希表1的空间
- Q:渐进式 rehash 是什么?
- 在第二步拷贝数据时,redis仍然正常处理客户端请求,每处理一个请求时,从哈希表1中的第一个索引位置开始,顺带着将这个索引位置上的所有entries拷贝到哈希表2中。等处理下一个请求时,再顺带拷贝哈希表1中的下一个索引位置的entries
03丨高性能IO模型:为什么单线程Redis能那么快?
- Q:Redis单线程指的是什么?
- Redis的网络IO和键值对读写是由一个线程来完成的,这也是Redis对外提供键值存储服务的主要流程
- Q:单线程Redis速度快的原因是什么?
- 1.大部分操作在内存上完成,加上采用的高效的数据结构(哈希表和跳表)
- 2.采用了多路复用机制,使其在网络IO操作中能并发处理大量的客户端请求
04丨AOF日志:宕机了,Redis如何避免数据丢失?
- Q:Redis持久化的两大机制是什么?
- AOF日志和RDB快照
- Q:AOF(Append Only File)的持久化是怎样的
- Redis 执行完一个写命令后,将写命令以协议文本的形式追加到 AOF 缓冲区末尾,再通过同步策略来决定是否将 AOF 缓冲区中的内容写入 & 同步到 AOF 日志
- 只有命令能执行成功,才会被记录到日志中。不会阻塞当前的写操作
- Q:AOF日记的记录内容是怎样的?
- 以
set testkey testvalue为例 *3表示当前命令有三个部分,每部分都是有$+数字开头,后面紧跟着具体的命令、键、值,此处的数字表示这部分中的命令、键和值一共有多少字节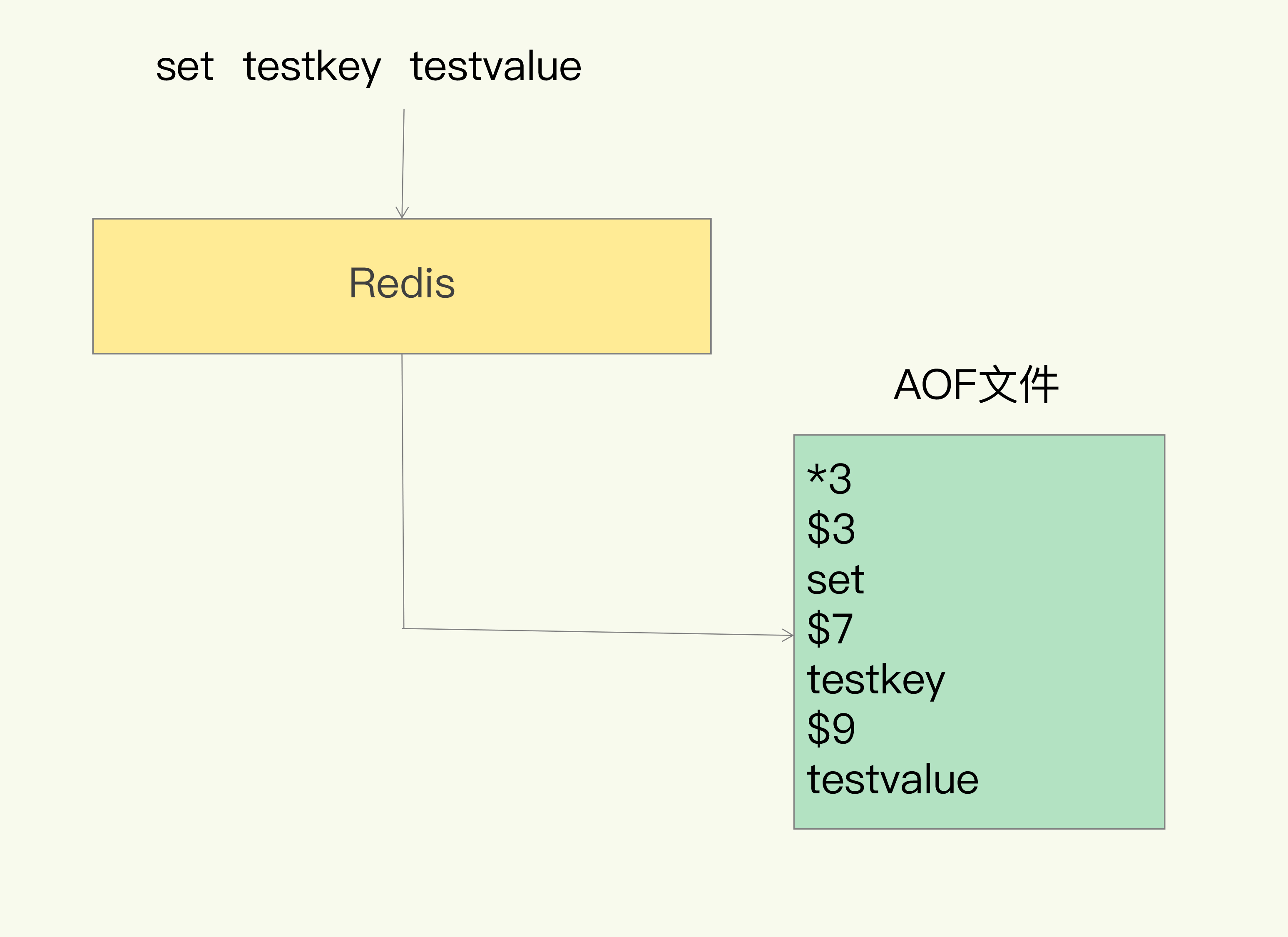
- 以
- Q:AOF的两个潜在风险是什么?
- 1.如果刚执行完一个命令,还没有来得及记日志就宕机了,那么这个命令和相应的数据就有丢失的风险
- 2.AOF虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险,这是因为,AOF日志也是在主线程中执行的,如果在把日志文件写入磁盘时,磁盘写压力大,就会导致写盘很慢,进而导致后续的操作也无法执行
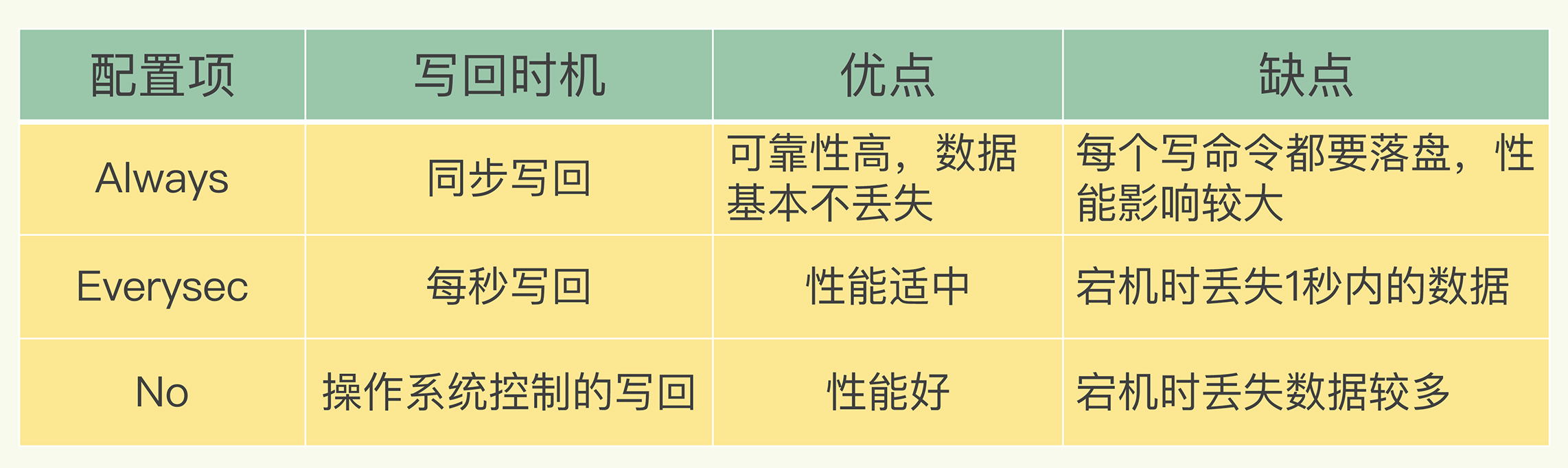
- Q:AOF日志有哪三种写回策略?(即配置项 appendfsync 的三个可选值)
- Always,同步写回:每个写命令执行完,立马将所有内容写入并同到 AOF 日志
- Everysec,每秒写回:每个写命令执行完,将 AOF 缓冲区中的所有内容写入到 AOF 日志,如果上次同步 AOF 日志的时间距离现在超过 1 秒,那么对 AOF 日志进行同步
- No,操作系统控制的写回:每个写命令执行完,将 AOF 缓冲区中的所有内容写入到 AOF 日志,但并不对 AOF 日志进行同步,何时同步由操作系统来决定
- Q:Redis 中的写入并同步到 AOF 日志的写入和同步的区别是什么
- 当写回策略为 always 的时候,Redis 源码逻辑为先调用 write 函数写入 AOF 日志文件,紧接着调用 fdatasync 函数对 AOF 日志文件进行同步,确保写入的内容同步到硬盘成功
- 当调用 write 函数的时候,数据只是写到了内存缓冲区中,用 fdatasync 函数可以强制让操作系统立即将内存缓冲区中的数据同步到硬盘中
- Q:AOF日志三种写回策略的优劣是什么?
- 同步写回:基本不丢数据,但在每一个写命令后都有一个慢速的落盘操作,不可避免地会影响主线程性能
- 每秒写回:采用一秒写回一次的频率,避免了「同步写回」的性能开销,虽然减少了对系统性能的影响,但若发生宕机,上一秒内未落盘的命令操作仍然会丢失
- 操作系统控制的写回:在写完缓冲区后,可以继续执行后续的命令,但是落盘的时机已经不在Redis手中了,只有AOF记录没有写回磁盘,一旦宕机对应的数据就丢失了
- Q:AOF文件过大带来的3个性能问题是什么?
- 1.文件系统本身对文件大小有限制, 无法保存过大的文件
- 2.如果文件太大,之后再往里面追加命令记录的话,效率也会变低
- 3.如果发生宕机,AOF 中记录的命令要一个个被重新执行,用于故障恢复,如果日志文件太大,整个恢复过程就会非常缓慢
- Q:AOF重写机制是什么?
- 在重写时,Redis根据数据库的现状创建一个新的AOF文件。
- 即读取数据库中的所有键值对,然后对每一个键值对用一条命令记录它的写入
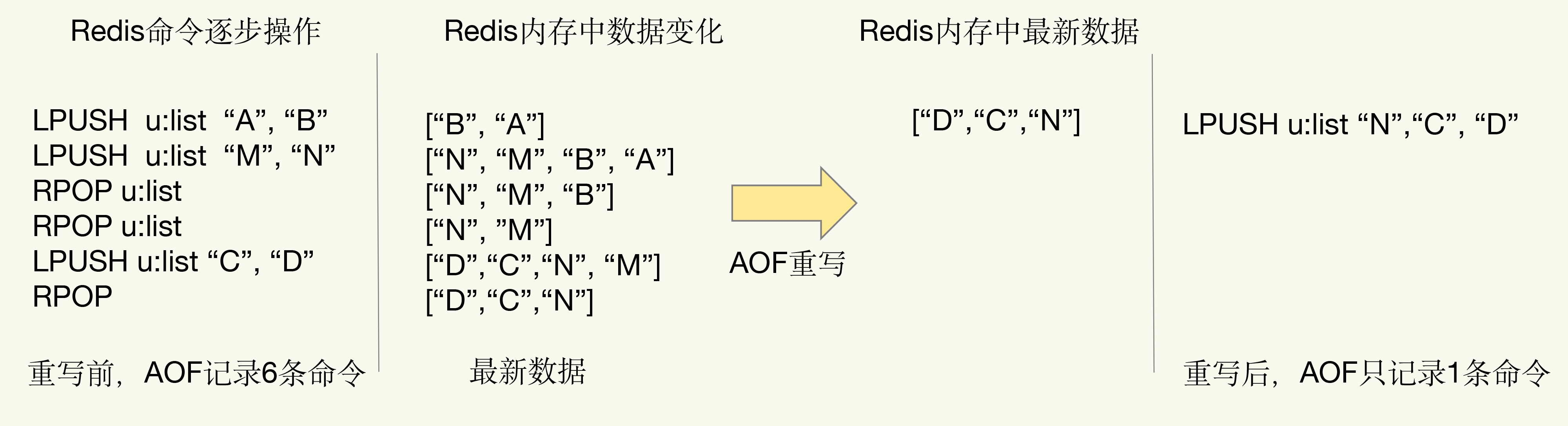
- Q:为什么重写机制可以把日志文件变小?
- 当一个键值对被多条写命令反复修改时,AOF文件会记录相应的多条命令
- 但在重写时,根据这个键值对当前的最新状态,为它生成对应的写入命令。这样,一个键值对在重写日志中只用一条命令即可
- 在日志恢复时,只用执行这条命令,就可以直接完成这个键值对的写入了
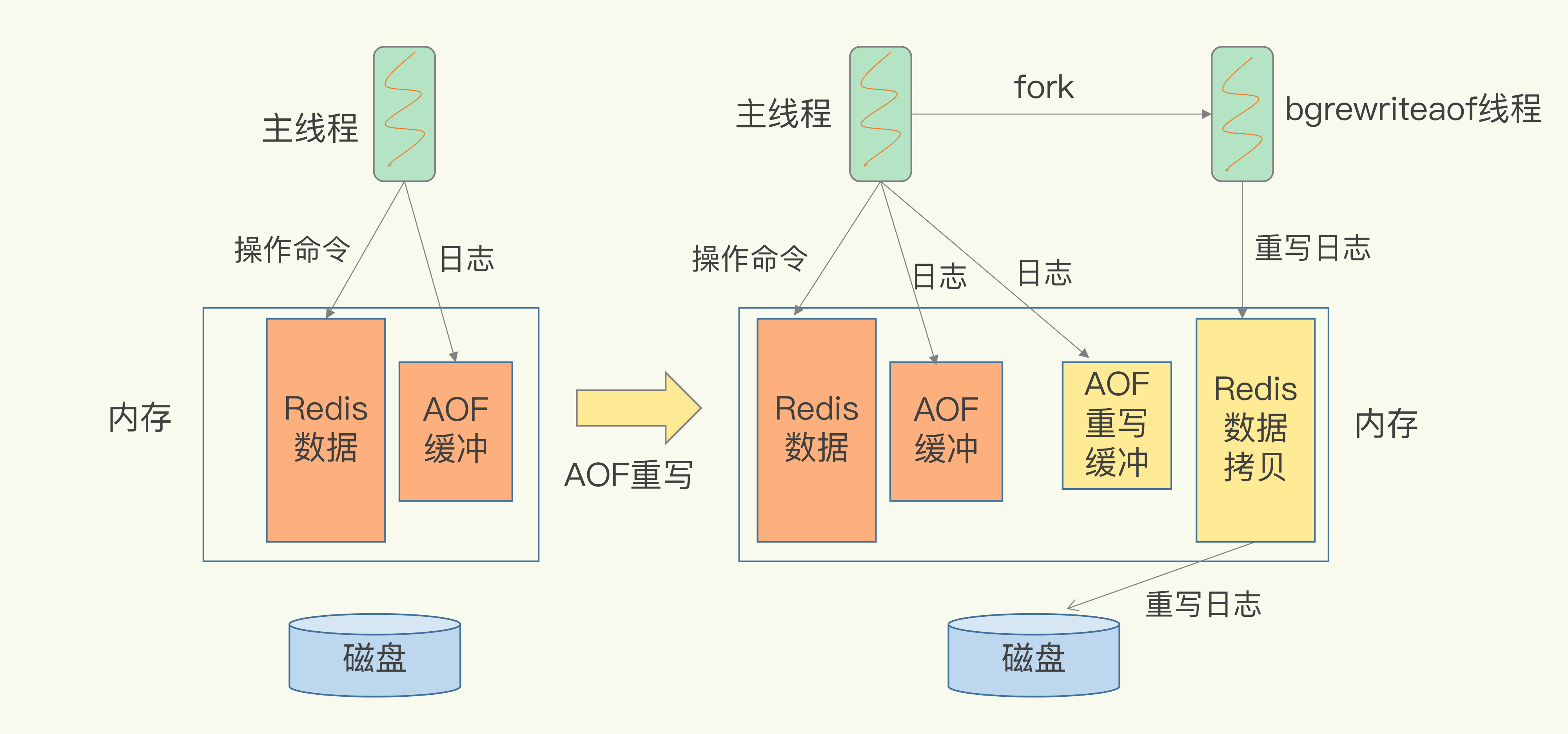
- Q:重写的过程是怎样的?
- 由后台线程bgrewriteaof完成,是为了避免阻塞主线程,导致数据库性能下降
- 一个拷贝
- 每次执行重写时,主线程fork出后台的bgrewriteaof子进程。fork会把主线程的内存拷贝一份给bgrewriteaof子进程,这里包含了数据库的最新数据
- bgrewriteaof子进程在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志
- 两处日志
- 1.正在使用的AOF日志:因主进程未阻塞,仍然可以处理新来的操作。此时若有写操作,Redis会把这个操作写到它的缓冲区。这样一来,即使宕机了,这个AOF日志的操作仍然是齐全的,可以用于恢复
- 2.新的AOF重写日志:这个操作也会被写到重写日志的缓冲区。这样,重写日志也不会丢失最新的操作。等到拷贝数据的所有操作记录重写完成后,重写日志记录的这些最新操作也会写入新的AOF文件,以保证数据库最新状态的记录。此时即可用新的AOF文件替代旧文件了
05丨内存快照:宕机后,Redis如何实现快速恢复?
- Q:RDB的持久化是怎样的?
- 作用是将某个时间点上的数据库状态保存到 RDB 文件中,RDB 文件是一个压缩的二进制文件,通过它可以还原某个时刻数据库的状态。由于 RDB 文件是保存在硬盘上的,所以即使 Redis 崩溃或者退出,只要 RDB 文件存在,就可以用它来还原数据库的状态
- Q:生成RDB文件的两个命令是什么?
- save:在主线程执行,会导致阻塞,直到 RDB 文件生成完毕,在进程阻塞期间,Redis 不能处理任何命令请求
- bgsave:创建一个子进程,专门用于写入RDB文件,避免了主线程的阻塞(默认配置)
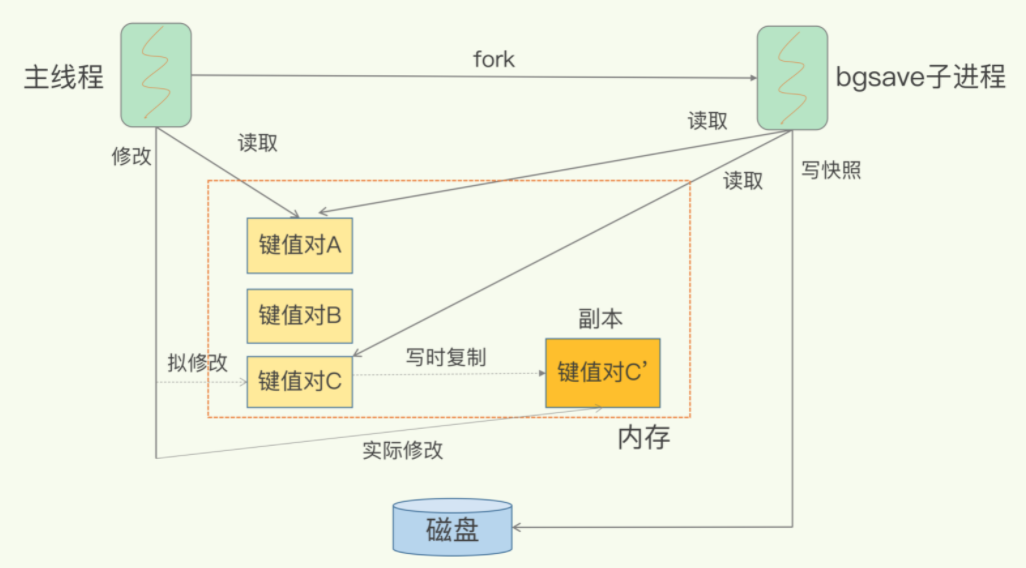
- Q:bgsave做快照时如何保证数据可修改?
- 借助操作系统提供的写时复制技术(Copy-On-Write, COW)
- bgsave子进程是由主线程fork生成的,可以共享主线程的所有内存数据。bgsave子进程运行后,开始读取主线程的内存数据,并把它们写入RDB文件
- 若主线程对这些数据也是读操作(图中键值对A),主线程和bgsave子线程互不影响
- 若主线程要修改一块数据(图中键值对C),那这块数据会被复制一份,生成该数据的副本C'。然后,主线程在这个数据副本上修改,同时,bgsave子进程会把原来的数据写入RDB文件
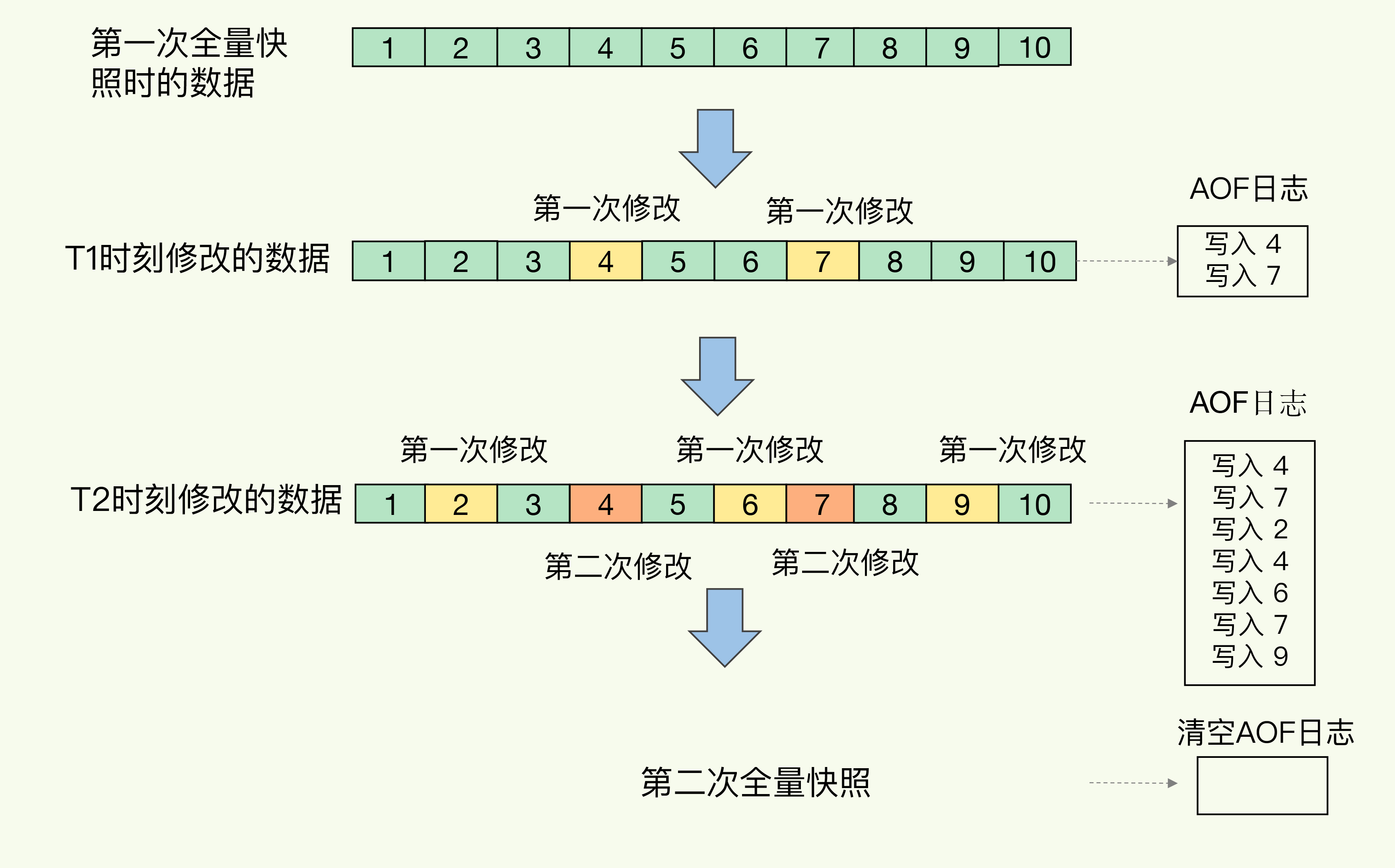
- Q:混合使用AOF日志和内存快照的方法是什么?
- 内存快照以一定的频率执行,在两次快照之间,使用AOF日志记录这期间的所有命令操作