
2、技术选型:创业初期,技术如何选型
- no2:创业初期架构特点、选型依据、选型建议是什么?
- 特点:
- 1.单机系统(All in one)
- 2.程序耦合(All in one)
- 3.逻辑核心是 CURD
- 主要依据:选择技术合伙人会的,熟悉的,是早期技术选型的
- 选型建议:
- PHP体系:Linux、Apache、MySQL、PHP
- Java 体系:Linux、Tomcat、MySQL、Java
- 特点:
- no2:创业初期工程师的主要矛盾是什么?如何解决?
- 矛盾:业务开发效率与质量低,CURD 频繁出错
- 解决:尽早引入 DAO/ORM 技术
- DAO(Data Access Object):像对象一样访问数据
- ORM(Object Relation Mapping):简化数据库查询过程

3、技术选型:框架组件要不要自研,什么时候自研?
- no3:框架组件要不要自研,什么时候自研?有哪 4 个观点?
- 1.早期不要自研,后期适当自定义
- 2.随着规模的扩大,要控制技术栈
- 3.建议浅浅的封装一层
- 4.随着业务规模,研发团队进一步扩大,适当造一些轮子
- no3:为什么说早期不建议自研?
- 1.早期的业务以快速迭代为最高优先级,快速实现功能,让公司活下来最重要
- 2.技术栈选择技术合伙人最熟悉的
- 研发语言:熟PHP选PHP,熟Java选Java
- 数据库:熟MySQL选MySQL,熟SQL-server选SQL-server
- 框架组件:熟Ruby on Rails选ROR,熟ThinkPHP选ThinkPHP,熟SSH选SSH
- 3.此时技术栈的选择对合伙人的技术视野有要求,能在未来少踩坑
- no3:为什么要控制技术栈?
- 1.绝对不能每个人想用什么就用什么,否则会造成混乱
- 2.即使用开源,技术栈也尽量统一
- no3:什么叫「浅浅封装一层」?好处是什么?
String Memcache::get(String key) String Memcache::set(String key, String value) String Memcache::del(String key) String 58DaojiaKV::get(String key) { String result = Memcache::get(key); return result; }- 好处
- 对调用方屏蔽底层实现细节
- 当底层变化的时候,调用方改动很小
- 能很方便实现统一的功能,如时间统计等
- 好处
- no3:为什么说随着业务规模和研发团队的扩大可以适当造一些轮子?而不能全部使用开源?
- 不同技术团队,痛点是相似的
- 开源解决不了全部个性化需求
- 有站点,监控服务的可用性,处理时间监控需求
- 有告警需求
- 有自动化发布,自动化运维需求
- 有服务治理,服务自动发现需求
- 有调用链跟踪需求
- 有SQL监控需求
- 有系统层面数据收集与可视化展现的需求
- 自研解决痛点,更贴合团队实际情况
- 开源框架/组件太重了,我们需要的可能只是一个轻量级的框架/组件
- 开源框架/组件,只能满足我们的一部分需求
- 不了解开源框架/组件的设计理念,要二次开发成本更高
- 有些通用的需求是和业务紧密结合的,开源框架/组件可能满足不了
4、容量设计:流量高低,对架构究竟有什么影响?
- no4:什么时候要进行容量评估?
- 1.容量有质变性增长
- 2.临时运营活动
- 3.新系统上线
- no4:哪些指标要进行容量预估?
- 看具体业务,对应到系统侧的主要矛盾是什么,如:
- 1.数据量
- 2.并发量,吞吐量
- 3.带宽
- 4.CPU/MEM/DISK 等
- no4:如何进行容量评估(以吞吐量为例)
- 1.评估总访问量:询问产品、运营
- 2.评估平均访问量:总量除以总时间,一天可算 4w 秒
- 3.评估高峰 QPS:可根据业务曲线图来
- 4.评估系统、单机极限 QPS:使用压测
- 5.根据线上冗余度做决策:计算需求和线上冗余度差值
5、伪分布式:你以为,多机就是分布式?
- no5:随着流量的提升,早期系统最先遇到的两大问题是什么?如何分析系统特点与瓶颈?
- 现象:人多的时候会卡(即慢,性能下降),压力会导致宕机(即一挂全挂,耦合严重)
- 瓶颈分析:网络带宽、内存、CPU 计算、磁盘 IO
- 初步结论:ALL in one 导致单机资源称为瓶颈
- no5:架构早期最快速地解决「单机资源瓶颈」问题的思路?做法?原因?
- 思路:
- 增加硬件资源(时间短),避免大规模代码重构(时间长)
- 做法:
- 把「单机」变「多机」,用最小的成本,扩展资源
- 原因:
- 此时最大的成本,是时间成本
- 能用“钱”解决的系统问题,往往不是问题
- 老板最不愿见到的,是解决一个系统问题, 花很长的时间(市场和投资人等不起)
- 思路:
- no5:「单机」变「多机」的伪分布式的「三大分离」应该怎么做?设计思路?没解决的问题?
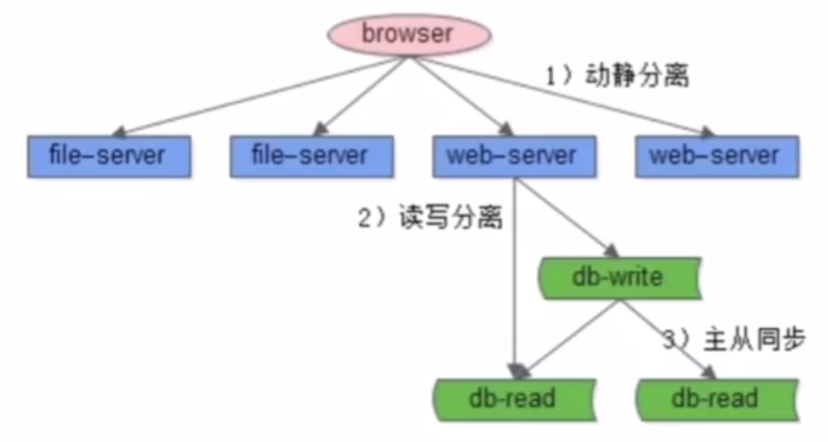
- 三大分离
- 1.读写分离(引发读写延时新问题):将数据库的读写请求分散到不同的数据库机器上
- 2.动静分离:将静态文件(css、jpg、静态页面)和动态生成的站点分离
- 3.前台后台分离:前台即用户访问的系统,后台即运营使用的系统
- 设计思路:用最快的速度,增加硬件资源,提升系统性能,增加访问速度
- 没解决的问题:
- 1.耦合问题:一个子系统挂了,仍然是全站挂
- 2.主从延时新问题:读写分离只能提升读写性能,无法降低单库数据量
- no5:如何解决「三大分离」的耦合问题和读写延时问题?设计思路?如何操作?
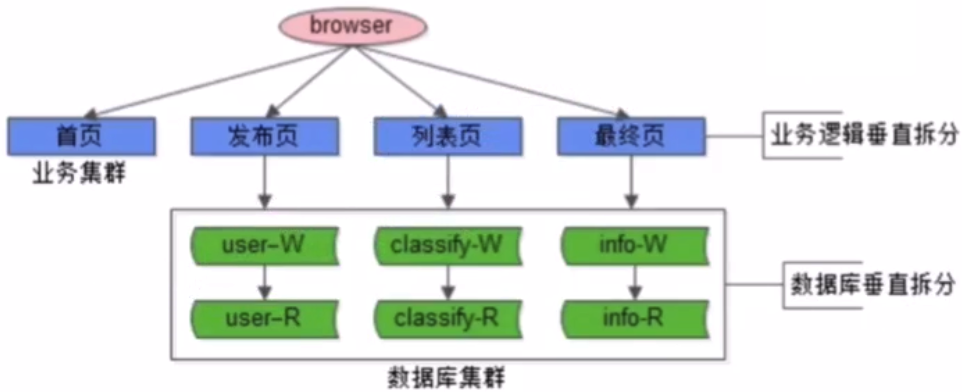
- 方案:业务垂直拆分,解耦
- 操作:
- 1.业务垂直拆分
- 2.代码垂直拆分(子系统耦合)
- 3.数据库垂直拆分(数据量降低,延时缓解)
- 4.研发团队垂直拆分(专业化,效率提升)
- 设计思路:用最快的速度,增加硬件资源,解耦
- 垂直拆分,会随着业务越来越复杂,不断持续地进行
- 存在问题
- 1.对同一个垂直站点子系统,仍然是一个「单体架构」,每一个业务都并不是高可用的,子系统的性能仍然受到单机资源的限制无法扩展
- 2.子系统不是高可用的,只能保证一个挂了,另一个不受影响